Hadoop版本:Hadoop-1.2.1
参考:《Hadoop技术内幕-深入解析Hadoop Common和HDFS架构设计与实现原理》
序列化作用:
- 作为一种持久化格式,可以存储在磁盘上,可以用来反序列化;
- 作为通信数据格式,在网络上传输;
- 作为一种拷贝,克隆机制,对象序列化到内存缓存区中,然后反序列化得到一个对已存对象进行深拷贝的新对象;
JAVA中的序列化
JAVA中类的序列化只需要实现Serializable接口,该接口只是一个说明性的接口,没有实际的方法。
序列化实现通过一对输入/输出流,序列化时在某种OutputStream对象的基础上创建一个ObjectOutputStream对象,然后调用writeObject执行序列化。
输出的序列化数据将保存在原来的OutputStream中,具体序列化的数据由writeObject方法负责。
对于Java基本类型的序列化,ObjectOutputStream提供了writeBoolean,writeByte等方法。
而反序列化的过程类似,将InputStream包装在ObjectInputStream中并调用readObject方法,返回一个Object类型的引用,通过向下转型,可以得到正确的结果。
JAVA序列化以后的对象所占数据过大,包括了很多与该对象相关联的信息,不过可以处理操作系统的差异,在Windows上序列化的对象,可以在UNIX上重建。1
2
3
4
5public class ClassA implements Serializable{...}
ClassA a=new ClassA...;//实现Serializable的类
ByteArrayOutputStream out=new ByteArrayOutputStream();//最终序列化结果输出到该流中
ObjectOutputStream objOut=new ObjectOutputStream(out);//包裹out创建ObjectOutputStream
objOut.writeObject(a);//序列化
可以看出实际的序列化过程是ObjectOutputStream的writeObject完成的,格式固定
Hadoop的序列化
Hadoop没有采用Java的序列化机制,引入了Writable接口,作为所有可序列化对象必须实现的接口。该接口不是声明性的接口,包含两个方法:1
2
3
4
5
6public interface Writable {
//序列化,结果写到实现了DataOutput接口的类中(流)
void write(DataOutput out) throws IOException;
//反序列化,从DataInput中读取
void readFields(DataInput in) throws IOException;
}
如HDFS中的Block类,实现了Writable接口1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class Block implements Writable, Comparable<Block> {
...
private long blockId;
private long numBytes;
private long generationStamp;
...
public void write(DataOutput out) throws IOException {
out.writeLong(blockId);
out.writeLong(numBytes);
out.writeLong(generationStamp);
}//分别将三个成员写到输出流中
...
public void readFields(DataInput in) throws IOException {
this.blockId = in.readLong();
this.numBytes = in.readLong();
this.generationStamp = in.readLong();
if (numBytes < 0) {
throw new IOException("Unexpected block size: " + numBytes);
}
}//从输入流中依次读取三个成员
那么,我们可以像下面这样对Block进行序列化操作1
2
3
4
5
6Block block=new Block(...);
ByteArrrayOutputStream out=new ByteArrayOutputStream();//最终输出到的流
DataOutputStream data=new DataOutputStream(out);//DataOutputStream,包裹out
block.write(data);//序列化
dout.close();
...
可见,这里具体的序列化需要我们自己实现,自己指定那些需要写到输出流中。
WritableComparable
WritableComparable提供了序列化功能的同时,还提供了比较功能,该接口在Hadoop中使用很频繁。
子类如Java基本类(IntWritable,FloatWritable,LongWritable等,VIntWritable,VLongWritable等变长基本类型),Text等,还包括MapReduce中用到的ID,TaskID,JobID等都需要序列化网络传输同时在需要排序时进行比较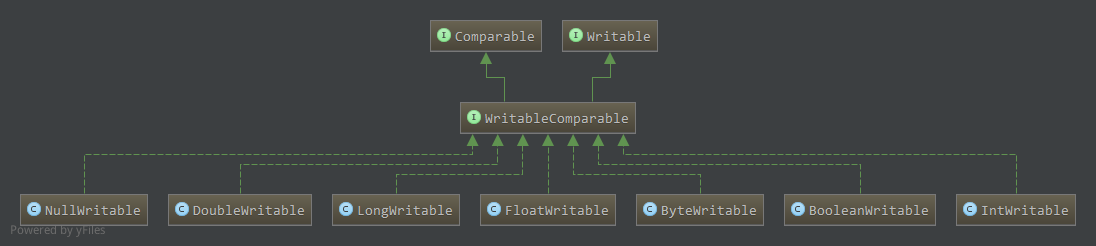
NullWritable
NullWritable对应null,没有公有的构造函数,只能通过静态成员函数get来获取一个NullWritable对象,即所谓的单例模式1
2
3
4
5public class NullWritable implements WritableComparable {
private static final NullWritable THIS = new NullWritable();
private NullWritable() {} // no public ctor
/** Returns the single instance of this class. */
public static NullWritable get() { return THIS; }
因为其对应的是null,因此hashCode为0,toString返回”null”,compareTo方法只能和另一个NullWritable对象比较,正常情况返回0。
相应的序列化反序列化方法write和readFields全都没有相应的操作。1
2
3
4
5
6
7
8
9
10
11
12
13
14public String toString() {
return "(null)";
}//字符串null
public int hashCode() { return 0; }//hash码为0
public int compareTo(Object other) {
if (!(other instanceof NullWritable)) {
throw new ClassCastException("can't compare " + other.getClass().getName()
+ " to NullWritable");
}
return 0;//只有在比较的对象为NullWritable时才返回0,不能与非NullWritable对象比较
}
public boolean equals(Object other) { return other instanceof NullWritable; }//NullWritable对象相等,单例
public void readFields(DataInput in) throws IOException {}//空操作
public void write(DataOutput out) throws IOException {}//空操作
在静态代码段中,注册该类的WritableComparator1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17static { // register this comparator
WritableComparator.define(NullWritable.class, new Comparator());
}
public static class Comparator extends WritableComparator {
public Comparator() {
super(NullWritable.class);
}
/**
* Compare the buffers in serialized form.
*/
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
assert 0 == l1;//长度为0
assert 0 == l2;//长度为0
return 0;//和compareTo一样,正常情况只会返回0
}
}
ByteWritable
对应一个字节,成员1
private byte value;
序列化和反序列化1
2
3
4
5
6
7public void readFields(DataInput in) throws IOException {
value = in.readByte();
}//反序列化,从DataInput中读取一个字节
public void write(DataOutput out) throws IOException {
out.writeByte(value);
}//序列化
ByteWritable之间比较1
2
3
4
5public int compareTo(Object o) {
int thisValue = this.value;
int thatValue = ((ByteWritable)o).value;
return (thisValue < thatValue ? -1 : (thisValue == thatValue ? 0 : 1));
}
toString方法1
2
3public String toString() {
return Byte.toString(value);
}
静态代码段中的注册1
2
3
4
5
6
7
8
9
10
11
12
13static { // register this comparator
WritableComparator.define(ByteWritable.class, new Comparator());
}
public static class Comparator extends WritableComparator {
public Comparator() {
super(ByteWritable.class);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
byte thisValue = b1[s1];
byte thatValue = b2[s2];
return (thisValue < thatValue ? -1 : (thisValue == thatValue ? 0 : 1));
}
}
其他的如IntWritable,LongWritable等整型的基本一样,只不过相应的读取4个字节,8个字节。
而浮点型Float的读取4个字节整型,然后转换为浮点型1
Float.intBitsToFloat(readInt(bytes, start));
浮点型Double的读取8个字节整型,转换为浮点型1
return Double.longBitsToDouble(readLong(bytes, start));
变长基本类型VIntWritable,VLongWritable
变长类型对实际数值比较小的整型,尽可能采用小的字节数序列化,更省空间。
主要看序列化和反序列化方法
序列化
1 | //VInt |
可见最终是通过writeVLong方法进行序列化。该方法使用零压缩编码方法序列化一个long型整型到二进制流中。
对于[-112,127]范围内的数据,序列化只需要使用1个字节。
而对于其他值,序列化时第一个字节显示该long型数值是正还是负,且显示了序列化该数值所用的字节数。
如果第一个字节v在[-120,-113]范围内,则该long型数值为正,字节数n为-(v+112)。
如果第一个字节v在[-128,-121]范围内,则该long型数值为负,字节数n为-(v+120)。
接下来的n个字节为该long型数值的序列化字节,使用高位非零字节在前的顺序(即高位的全0字节不序列化)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public static void writeVLong(DataOutput stream, long i) throws IOException {
if (i >= -112 && i <= 127) {//一个字节便可表示
stream.writeByte((byte)i);
return;
}
int len = -112;
if (i < 0) {
i ^= -1L; // take one's complement'
len = -120;
}
long tmp = i;
while (tmp != 0) {
tmp = tmp >> 8;
len--;
}//此时,len值保存了该long型数值的正负性和所需字节数信息
stream.writeByte((byte)len);//输出len值
len = (len < -120) ? -(len + 120) : -(len + 112);//实际所需字节数据
//输出序列化字节
for (int idx = len; idx != 0; idx--) {
int shiftbits = (idx - 1) * 8;
long mask = 0xFFL << shiftbits;
stream.writeByte((byte)((i & mask) >> shiftbits));
}
}
反序列化
1 | //VInt |
通过readVLong反序列化1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public static long readVLong(DataInput stream) throws IOException {
byte firstByte = stream.readByte();//读第一个字节
int len = decodeVIntSize(firstByte);//序列化字节长度
if (len == 1) {//序列化一个字节
return firstByte;
}
long i = 0;
//序列化为多个字节,分别读取
for (int idx = 0; idx < len-1; idx++) {
byte b = stream.readByte();
i = i << 8;
i = i | (b & 0xFF);
}
return (isNegativeVInt(firstByte) ? (i ^ -1L) : i);//正负极性
}
public static int decodeVIntSize(byte value) {
if (value >= -112) {
return 1;
} else if (value < -120) {
return -119 - value;
}
return -111 - value;
}
根据序列化过程,很简单得到反序列化过程。decodeVIntSize根据第一个字节得到序列化字节的长度。
Text
使用标准的UTF8编码存储文本,提供对文本字节级别的序列化,反序列化和比较等方法。还提供在不将字节数组转换为字符串的情况下的字符串反转。
也包括了序列化/反序列化一个字符串,编码/解码一个字符串,检查一个字节数组是否包含合法的UTF8编码,计算一个已经编码过字符串的长度等工具方法。
成员
包括两个线程独立的编码工厂ENCODER_FACTORY和解码工厂DECODER_FACTORY1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17private static ThreadLocal<CharsetEncoder> ENCODER_FACTORY =
new ThreadLocal<CharsetEncoder>() {
protected CharsetEncoder initialValue() {
return Charset.forName("UTF-8").newEncoder().
onMalformedInput(CodingErrorAction.REPORT).
onUnmappableCharacter(CodingErrorAction.REPORT);
}
};//编码工厂
private static ThreadLocal<CharsetDecoder> DECODER_FACTORY =
new ThreadLocal<CharsetDecoder>() {
protected CharsetDecoder initialValue() {
return Charset.forName("UTF-8").newDecoder().
onMalformedInput(CodingErrorAction.REPORT).
onUnmappableCharacter(CodingErrorAction.REPORT);
}
};//解码工厂
使用字节数组存储文本数据,并记录长度1
2
3private static final byte [] EMPTY_BYTES = new byte[0];//默认构造
private byte[] bytes;//存储字节级别数据
private int length;//长度
编解码
编码(文本或字符串转字节数组)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public static ByteBuffer encode(String string) throws CharacterCodingException {
return encode(string, true);
}
public static ByteBuffer encode(String string, boolean replace) throws CharacterCodingException {
CharsetEncoder encoder = ENCODER_FACTORY.get();//编码工厂获取字符集编码器CharsetEncoder
if (replace) {//如果支持替换,则异常输入被替换为"U+FFFD",这里设置异常输入和未映射的字符支持替换
encoder.onMalformedInput(CodingErrorAction.REPLACE);
encoder.onUnmappableCharacter(CodingErrorAction.REPLACE);
}
ByteBuffer bytes = encoder.encode(CharBuffer.wrap(string.toCharArray()));//编码器编码
if (replace) {//支持替换的话,编码后设置编码器为原来默认采用"报告"形式
encoder.onMalformedInput(CodingErrorAction.REPORT);
encoder.onUnmappableCharacter(CodingErrorAction.REPORT);
}
return bytes;
}解码(字节数组转字符串)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public static String decode(byte[] utf8) throws CharacterCodingException { return decode(ByteBuffer.wrap(utf8), true); }
public static String decode(byte[] utf8, int start, int length) throws CharacterCodingException {
return decode(ByteBuffer.wrap(utf8, start, length), true);
}
private static String decode(ByteBuffer utf8, boolean replace) throws CharacterCodingException {
CharsetDecoder decoder = DECODER_FACTORY.get();//解码器工厂获得字符集解码器
if (replace) {//同编码过程一样,支持replace的话,异常输入和未映射的字符替换为"U+FFFD"。
decoder.onMalformedInput(java.nio.charset.CodingErrorAction.REPLACE);
decoder.onUnmappableCharacter(CodingErrorAction.REPLACE);
}
String str = decoder.decode(utf8).toString();//解码
// set decoder back to its default value: REPORT
if (replace) {//支持replace时,重新设置为REPORT
decoder.onMalformedInput(CodingErrorAction.REPORT);
decoder.onUnmappableCharacter(CodingErrorAction.REPORT);
}
return str;
}
构造
缺省构造
缺省构造方法,创建空字节数组1
public Text() { bytes = EMPTY_BYTES; }
通过String构造
1
2
3
4
5
6
7
8
9
10
11public Text(String string) { set(string); }
public void set(String string) {
try {
ByteBuffer bb = encode(string, true);//编码成ByteBuffer
bytes = bb.array();
length = bb.limit();
}catch(CharacterCodingException e) {
throw new RuntimeException("Should not have happened " + e.toString());
}
}给定一个String,将String转为char数组,包裹成CharBuffer,通过NIO的CharsetEncoder进行编码,编码器通过线程独立静态成员ENCODER_FACTORY获得。关于ByteBuffer或CharBuffer另见NIO缓冲区
从其他Text构造
1
2
3
4
5
6
7public Text(Text utf8) { set(utf8); }
public void set(Text other) { set(other.getBytes(), 0, other.getLength()); }
public void set(byte[] utf8, int start, int len) {//简单的将其他Text字节数组进行拷贝
setCapacity(len, false);
System.arraycopy(utf8, start, bytes, 0, len);
this.length = len;
}直接从字节数组构造
1
public Text(byte[] utf8) { set(utf8); }//简单拷贝
数据操作
数组容量变更
1
2
3
4
5
6
7
8
9
10
11//len小于当前字节数组长度无需改变,否则重新分配一个新的字节数组,并根据keepData决定是否保持原来字节数组的数据,保持的话拷贝原来数据
//到新的字节缓冲中
private void setCapacity(int len, boolean keepData) {
if (bytes == null || bytes.length < len) {
byte[] newBytes = new byte[len];
if (bytes != null && keepData) {
System.arraycopy(bytes, 0, newBytes, 0, length);
}
bytes = newBytes;
}
}数据追加
1
2
3
4
5public void append(byte[] utf8, int start, int len) {
setCapacity(length + len, true);
System.arraycopy(utf8, start, bytes, length, len);
length += len;
}utf8数组从start位置长度为len的数据追加到字节数组中
数据清除
1
public void clear() { length = 0; }//简单的将长度置为0
转字符串
1
2
3
4
5
6
7public String toString() {
try {
return decode(bytes, 0, length);
} catch (CharacterCodingException e) {
throw new RuntimeException("Should not have happened " + e.toString());
}
}字节数组转字符串对应解码过程,过程如上。其中的ByteBuffer和CharBuffer另见NIO缓冲区。
其他
验证字节数组是否为标准UTF8格式1
2
3public static void validateUTF8(byte[] utf8) throws MalformedInputException {
validateUTF8(utf8, 0, utf8.length);
}给定一个字符串,计算该字符串对应UTF8对应字节长度
1
public static int utf8Length(String string)
序列化/反序列化
1 | public void write(DataOutput out) throws IOException { |
序列化时,先输出可变长度int型的长度length,然后输出字节数组数据。反序列化时,同样的先读字节数组长度,设置容量(不保存原来数据),然后读字节数组数据。
其他一些高阶的序列化/反序列化操作
从流中读字符串
1
2
3
4
5
6public static String readString(DataInput in) throws IOException {
int length = WritableUtils.readVInt(in);//读取字符串长度
byte [] bytes = new byte[length];
in.readFully(bytes, 0, length);//读取字符串字节数据
return decode(bytes);//解码,字节数组转换为字符串
}字符串的序列化输出
1
2
3
4
5
6
7public static int writeString(DataOutput out, String s) throws IOException {
ByteBuffer bytes = encode(s);//字符串编码为ByteBuffer
int length = bytes.limit();
WritableUtils.writeVInt(out, length);
out.write(bytes.array(), 0, length);
return length;
}
比较
注册比较器1
2
3
4
5
6
7
8
9
10
11
12
13
14
15static {
// register this comparator
WritableComparator.define(Text.class, new Comparator());
}
public static class Comparator extends WritableComparator {
public Comparator() {
super(Text.class);
}
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
int n1 = WritableUtils.decodeVIntSize(b1[s1]);//n1为第一个Text length字段所占字节数
int n2 = WritableUtils.decodeVIntSize(b2[s2]);//n2为第二个Text length字段所占字节数
return compareBytes(b1, s1+n1, l1-n1, b2, s2+n2, l2-n2);
}
}
Text的比较器直接支持字节级别的比较,不需要反序列化为Text进行比较。序列化时,先写长度,且长度是通过可变长度的方式序列化的,因此从读取的第一个字节获取长度字段所占字节数。compareBytes为WritableComparator这父类中的方法,字节级别的比较。
ObjectWritable
ObjectWritable针对基本类型,字符串(Text),空值(NullWritable)等Writable的其他子类提供了封装,能够对封装在ObjectWritable中不同对象进行不同处理,适用于字段需要使用多种类型。典型的应用于Hadoop远程过程调用参数的序列化和反序列化。
成员属性
1 | private Class declaredClass;//被封装的类 |
序列化
1 | public void write(DataOutput out) throws IOException { |
序列化时,每种类型都先写出declaredClass声明类的类名,然后对不同的类型输出不同内容:
- null,”NullInstance”+declaredClass名字.null会创建相应的NullWritable对象,作为Writable的子类,对应下面情况
- 数组,元素长度+每一个元素,每一个数组元素作为对象调用
writeObject写出 - String,字符串数据
- Boolean,1字节数据(0或1)
- Character,2字节数据
- Byte,1字节数据
- Short,2字节数据
- Int,4字节数据
- Long,8字节数据
- Float,4字节数据
- Double,8字节数据
- Void,无后续输出(即只输出
declaredClass名字) - Enum,枚举的name属性
- Writable子类,实例对应的类名+该子类序列化方法write的输出,null也为这种情况
以上情况中,对于本原类型Boolean,Character,Byte,Short,Int,Long,Float,Double写出的字节数据都是通过DataOutput的相应方法write*输出的。而对于Writable的子类还需输出实例对应的类名,因为declaredClass可能对应为其父类类名,然后通过自己的序列化方法写出实际数据。
反序列化
1 | public void readFields(DataInput in) throws IOException { readObject(in, this, this.conf); } |
以上,有了序列化过程,便很好理解。首先读取类名,得到相应的类。
如果是本原类型,则通过DataInput的read*方法获取相应字节的数据反序列化对象,对于是Void的,实例为null。
如果是数组,读取数组长度,然后通过Array.newInstance创建数组(数组类型已知),接着便是通过readObject一个一个读数组元素对象。
如果是Writable子类,先读实例名,通过WritableFactories创建相应实例,然后相应实例readFields方法反序列化数据。null也对应此种情况,不过null序列化时对应创建NullWritable,其序列化函数输出其declaredClass。
WritableFactories拥有静态成员CLASS_TO_FACTORY,维护了所有可序列化类对应的工厂。1
private static final HashMap<Class, WritableFactory> CLASS_TO_FACTORY = new HashMap<Class, WritableFactory>();
如果需要使用工厂创建相应类的实例,需注册类对应的工厂,工厂继承WritableFactory类实现newInstance的方法,WritableFactories的newInstance方法如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14public static Writable newInstance(Class<? extends Writable> c, Configuration conf) {
WritableFactory factory = WritableFactories.getFactory(c);//该类注册了对应的工厂类
if (factory != null) {//注册了工厂类的话,使用工厂类的newInstance方法,因此注册时工厂类应该继承WritableFactory类实现newInstance方法
Writable result = factory.newInstance();//使用工厂类创建实例
if (result instanceof Configurable) {//如果是可配置的,配置
((Configurable) result).setConf(conf);
}
return result;
} else {//没有对应的工厂类,使用反射创建实例
return ReflectionUtils.newInstance(c, conf);
}
}
public static synchronized WritableFactory getFactory(Class c) { return CLASS_TO_FACTORY.get(c); }
注册工厂通过静态方法setFactory1
public static synchronized void setFactory(Class c, WritableFactory factory) { CLASS_TO_FACTORY.put(c, factory); }
WritableComparator
WritableComparator为WritableComparable对应的比较器,类图如下: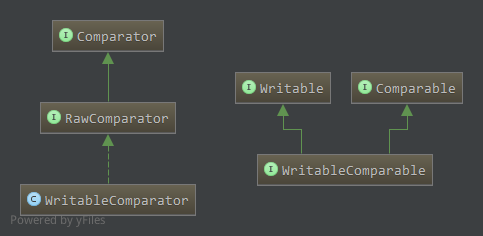
RawComparator继承自Comparator比较器,提供了字节层面上的比较,即允许直接比较流中未被反序列化的对象,从而省去了创建对象的开销1
2
3public interface RawComparator<T> extends Comparator<T> {
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}
而WritableComparator对应为WritableComparable的比较器,继承自RawComparator。不仅可以先反序列化流中数据,然后进行比较,同时提供了直接读取流中数据进行比较的功能。
成员
1 | private static HashMap<Class, WritableComparator> comparators = new HashMap<Class, WritableComparator>(); // registry |
静态成员comparators维护了所有的”WritableComparable-WritableComparator”键值对,可通过define静态成员函数注册一个键值对1
2
3public static synchronized void define(Class c, WritableComparator comparator) {
comparators.put(c, comparator);
}
keyClass为本对象对应的WritableComparable类key1,key2暂存反序列化的结果,用于比较buffer可重用的DataInput缓冲,实际存储数据的为byte数组(ByteArrayInputStream)
构造
1 | protected WritableComparator(Class<? extends WritableComparable> keyClass) { |
比较
1 | public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) { |
如上,将byte数组分别反序列化为相应的WritableComparable,然后使用继承的Comparable方法进行比较
还提供了字节层面的字典序比较方法compareBytes1
2
3
4
5
6
7
8
9
10
11
12public static int compareBytes(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
int end1 = s1 + l1;
int end2 = s2 + l2;
for (int i = s1, j = s2; i < end1 && j < end2; i++, j++) {
int a = (b1[i] & 0xff);
int b = (b2[j] & 0xff);
if (a != b) {
return a - b;
}
}
return l1 - l2;
}
Hadoop序列化框架
除了Java序列化和Hadoop中的Writable机制,还有其他序列化框架,如Hadoop Avro,Apache Thrift和Google Protocol Buffer等。
Hadoop提供了一个简单的序列化框架API,用于集成各种序列化实现,该框架由Serialization实现。
Serialization使用抽象工厂的设计模式,通过Serialization可以获得类型的Serializer实例,将一个对象转换为一个字节流的实现。也可以获得Deserializer实例,将字节流转换为对象。1
2
3
4
5
6
7
8public interface Serialization<T> {
//判断序列化实现是否支持该类对象
boolean accept(Class<?> c);
//获取序列化对象的Serializer实现
Serializer<T> getSerializer(Class<T> c);
//获取反序列化对象的DeSerializer实现
Deserializer<T> getDeserializer(Class<T> c);
}
Serializer接口如下1
2
3
4
5
6
7
8public interface Serializer<T> {
//为序列化做准备
void open(OutputStream out) throws IOException;
//序列化对象到底层输出流
void serialize(T t) throws IOException;
//关闭输出流,清理资源
void close() throws IOException;
}
Deserializer接口如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public interface Deserializer<T> {
//反序列化准备
void open(InputStream in) throws IOException;
/**
* <p>
* Deserialize the next object from the underlying input stream.
* If the object <code>t</code> is non-null then this deserializer
* <i>may</i> set its internal state to the next object read from the input
* stream. Otherwise, if the object <code>t</code> is null a new
* deserialized object will be created.
* </p>
* @return the deserialized object
*/
//从底层输入流中反序列化下一个对象
T deserialize(T t) throws IOException;
//关闭底层输入流,清理资源
void close() throws IOException;
}
目前Hadoop支持两个Serialization实现,分别是WritableSerialization(Writable机制)和Java序列化的JavaSerialization。
实现如下:1
2
3
4
5
6
7
8
9public boolean accept(Class<?> c) {
return Writable.class.isAssignableFrom(c);
}
public Deserializer<Writable> getDeserializer(Class<Writable> c) {
return new WritableDeserializer(getConf(), c);
}
public Serializer<Writable> getSerializer(Class<Writable> c) {
return new WritableSerializer();
}
而WritableSerializer如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16static class WritableSerializer implements Serializer<Writable> {
private DataOutputStream dataOut;
public void open(OutputStream out) {//open时提供输出流
if (out instanceof DataOutputStream) {
dataOut = (DataOutputStream) out;
} else {
dataOut = new DataOutputStream(out);
}
}
public void serialize(Writable w) throws IOException {
w.write(dataOut);//实际序列化为Writable的write方法
}
public void close() throws IOException {
dataOut.close();
}
}
WritableDeserializer如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28static class WritableDeserializer extends Configured implements Deserializer<Writable> {
private Class<?> writableClass;
private DataInputStream dataIn;
public WritableDeserializer(Configuration conf, Class<?> c) {
setConf(conf);
this.writableClass = c;
}
public void open(InputStream in) {
if (in instanceof DataInputStream) {
dataIn = (DataInputStream) in;
} else {
dataIn = new DataInputStream(in);
}
}
public Writable deserialize(Writable w) throws IOException {
Writable writable;
if (w == null) {//null的话创建相应的实例
writable = (Writable) ReflectionUtils.newInstance(writableClass, getConf());
} else {//非null使用w
writable = w;
}
writable.readFields(dataIn);//反序列化
return writable;
}
public void close() throws IOException {
dataIn.close();
}
}