Hadoop版本:Hadoop-1.2.1
参考:《Hadoop技术内幕-深入解析Hadoop Common和HDFS架构设计与实现原理》
在NameNode实现源码分析—区块和数据节点相关数据结构中分析了NameNode中维护的与区块和数据节点相关的数据结构,其中neededReplications管理着当前需要复制的区块信息,区块副本数没有达到期望值需要复制时会添加到该结构中。recentInvalidateSets管理着需要删除的区块信息,区块删除时添加到该结构中。
在NameNode中由FSNamesystem的ReplicationMonitor线程负责处理neededReplications和recentInvalidateSets中的区块。
对于neededReplications中区块信息,每次根据优先级取出一定数量的区块,然后选择源数据节点和目标数据节点,将复制信息添加到源数据节点的待复制区块队列replicateBlocks中,然后在数据节点心跳到来时发送区块复制命令。正在执行复制操作的区块信息同时添加到pendingReplications中进行管理,复制失败的区块会重新添加到neededReplications中。
而对于recentInvalidateSets中的区块,因为维护了其所属的数据节点,每次从中选取一定数量的数据节点,并选取数据节点中需要删除区块,添加到数据节点的待删除区块队列invalidateBlocks中,下次心跳到来时,发送区块删除命令。
本文分析ReplicationMonitor线程的实现
1. ReplicationMonitor线程
FSNamesystem成员replthread对应的线程,负责recentInvalidateSets和neededReplications相关操作,即区块删除和复制,初始化如下1
2
3this.replmon = new ReplicationMonitor();
this.replthread = new Daemon(replmon);
replthread.start();
线程如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public void run() {
while (fsRunning) {
try {
computeDatanodeWork();
processPendingReplications();
Thread.sleep(replicationRecheckInterval);
} catch (InterruptedException ie) {
LOG.warn("ReplicationMonitor thread received InterruptedException" + ie);
break;
} catch (IOException ie) {
LOG.warn("ReplicationMonitor thread received exception. " + ie + " " +
StringUtils.stringifyException(ie));
} catch (Throwable t) {
LOG.warn("ReplicationMonitor thread received Runtime exception. " + t + " " +
StringUtils.stringifyException(t));
Runtime.getRuntime().exit(-1);
}
}
}
每过replicationRecheckInterval进行一次操作,replicationRecheckInterval为FSNamesystem成员,默认3s1
this.replicationRecheckInterval = conf.getInt("dfs.replication.interval", 3) * 1000L;
主要的工作由computeDatanodeWork完成,processPendingReplications将pendingReplications线程PendingReplicationMonitor检测到复制超时的区块重新添加到neededReplications中。
2. computeDatanodeWork
1 | public int computeDatanodeWork() throws IOException { |
如上,blocksProcess为一次可以处理复制的区块数,每个数据节点处理个数由配置项dfs.namenode.replication.work.multiplier.per.iteration,默认一次一个数据节点处理两个
nodesToProcess为一次可以处理删除操作的节点数,由配置项dfs.namenode.invalidate.work.pct.per.iteration决定,默认0.32,即每次处理32%的数据节点的删除操作。
复制操作由computeReplicationWork负责,删除操作由computeInvalidateWork完成
3. computeReplicationWork复制操作
1 | private int computeReplicationWork(int blocksToProcess) throws IOException { |
如上,首先通过chooseUnderReplicatedBlocks从neededReplications中按照优先级选择最多blocksToProcess个待复制的区块,然后对每一个区块通过computeReplicationWorkForBlock进行处理。
如果给定Block是成功添加到选取的源数据节点待复制区块队列中,则能够在下一次心跳到来时发送复制命令,执行复制,此时computeReplicationWorkForBlock返回true。而如果发现因为种种原因不能执行复制,返回false。因此computeReplicationWork返回值就是有效的添加执行复制操作的区块数。
3.1 chooseUnderReplicatedBlocks选择待复制区块
1 | synchronized List<List<Block>> chooseUnderReplicatedBlocks(int blocksToProcess) { |
如上,因为neededReplications有三个优先级队列,因此结果列表也分配了三个优先级队列。
通过neededReplications创建的迭代器,会根据优先级获取下一个Block(从neededReplications.get(0)开始),然后定位到上次结束的下一个位置,由replIndex标识,就可以开始获取待复制的Block了。
如果到达neededReplications的尾部,则从头开始获取Block,重新创建迭代器。由前面neededReplications的相关分析可知,neededReplications中的Block在副本数达到期望值时(判断时机见前面),或者区块对应元数据不存在时会从neededReplications中移除,因此存在neededReplications的Block就是需要进行复制的,例如某个区块有效副本数为1,在优先级最高的队列中,进行了一次复制操作后,副本数没有达到3,还是存在neededReplications中,只不过因为执行了复制操作,不是在最高优先级的队列中了。因此达到尾部了可以从头循环读取Block进行复制操作。
3.2 computeReplicationWorkForBlock对每个待复制区块进行处理
computeReplicationWorkForBlock中首先选取源数据节点,做相应的检查1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30synchronized (this) {
synchronized (neededReplications) {
fileINode = blocksMap.getINode(block);
//Block对应的文件不存在,或者文件正在写,不能复制,从neededReplications中移除,返回false
if(fileINode == null || fileINode.isUnderConstruction()) {
neededReplications.remove(block, priority); // remove from neededReplications
replIndex--;
return false;
}
requiredReplication = fileINode.getReplication();
containingNodes = new ArrayList<DatanodeDescriptor>();
NumberReplicas numReplicas = new NumberReplicas();
srcNode = chooseSourceDatanode(block, containingNodes, numReplicas);//获取源数据节点
if ((numReplicas.liveReplicas() + numReplicas.decommissionedReplicas()) <= 0) {
missingBlocksInCurIter++;
}
if(srcNode == null) //没有源数据节点可以用来复制,返回false
return false;
//有效副本数加正在复制的副本数已经满足了副本期望值,不需要复制,从neededReplications中移除,返回false
numEffectiveReplicas = numReplicas.liveReplicas() + pendingReplications.getNumReplicas(block);
if(numEffectiveReplicas >= requiredReplication) {
neededReplications.remove(block, priority); // remove from neededReplications
replIndex--;
NameNode.stateChangeLog.info("BLOCK* Removing " + block + " from neededReplications as it has enough replicas");
return false;
}
}
}
如上,首先检查对应的文件是否存在,如果不存在或者文件正在写,则不能执行复制,从neededReplications中移除记录并返回false。
然后通过chooseSourceDatanode选择源数据节点,并统计副本信息NumberReplicas,如果没有可以复制的源数据节点,则不能复制返回false。或者说当前有效副本数加上正在复制的副本数已经达到了期望值,不需要复制,从neededReplications中移除并返回false。
3.2.1 选择源数据节点
chooseSourceDatanode如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45private DatanodeDescriptor chooseSourceDatanode(Block block,
List<DatanodeDescriptor> containingNodes, NumberReplicas numReplicas) {
containingNodes.clear();
DatanodeDescriptor srcNode = null;
int live = 0;
int decommissioned = 0;
int corrupt = 0;
int excess = 0;
Iterator<DatanodeDescriptor> it = blocksMap.nodeIterator(block);//Block的数据节点迭代器
Collection<DatanodeDescriptor> nodesCorrupt = corruptReplicas.getNodes(block);//Block对应的损坏信息
while(it.hasNext()) {
DatanodeDescriptor node = it.next();
Collection<Block> excessBlocks = excessReplicateMap.get(node.getStorageID());//超过期望副本数信息
if ((nodesCorrupt != null) && (nodesCorrupt.contains(node)))
corrupt++;//区块损坏的数据节点计数
else if (node.isDecommissionInProgress() || node.isDecommissioned())
decommissioned++;//区块所属正在退役或已经退役的数据节点计数
else if (excessBlocks != null && excessBlocks.contains(block)) {
excess++;//所在数据节点上区块超过期望副本数计数,应该删除,不是有效的副本
} else {
live++;//有效副本
}
containingNodes.add(node);
if ((nodesCorrupt != null) && nodesCorrupt.contains(node))//区块损坏,数据节点不能作为源数据节点
continue;
if(node.getNumberOfBlocksToBeReplicated() >= maxReplicationStreams)//数据节点正在复制的区块达到阈值,不能作为源数据节点
continue; // already reached replication limit
if(excessBlocks != null && excessBlocks.contains(block))//数据节点上区块副本属于超过期望值的,需要删除,不能作为源数据节点
continue;
if(node.isDecommissioned())//数据节点已经退役,不能作为源数据节点
continue;
if(node.isDecommissionInProgress() || srcNode == null) {//优先选择正在退役状态的数据节点
srcNode = node;
continue;
}
if(srcNode.isDecommissionInProgress())
continue;
//没有选择到正在退役状态的数据节点,随机选择一个可用数据节点
if(r.nextBoolean())
srcNode = node;
}
if(numReplicas != null)
numReplicas.initialize(live, decommissioned, corrupt, excess);//更新副本状态
return srcNode;
}
如上,containingNodes是该区块副本所有所在的数据节点,不管是否有效。
选择时,不选择已经处于DECOMMISSIONED即退役的数据节点,不选择所在区块已经损坏的数据节点,不选择正在执行的复制操作达到阈值的数据节点,不选择所在区块为超过副本期望值应该删除的数据节点。优先选择处于DECOMMISSION_INPROGRESS状态的数据节点,因为没有写数据流量(不会有其他节点往该数据节点写数据),相对其他数据节点更闲一点。如果没有选择到DECOMMISSION_INPROGRESS的数据节点,则从剩余可用数据节点中随机选择一个。
在选择源数据节点时还会更新区块副本状态NumberReplicas对象,如下1
2
3
4private int liveReplicas;//有效副本数
private int decommissionedReplicas;//已撤销或正在撤销节点上的副本数
private int corruptReplicas;//损坏副本数
private int excessReplicas;//超过期望副本值的副本数
如上,处于已撤销或正在撤销节点上的副本,损坏的副本,超过期望副本值的副本都不是有效副本。
这里在选择源数据节点之前的副本状态更新是很有必要的,确保确实需要执行复制操作。想象这样一种情况,某个数据节点被撤销了,因此所有区块都不是有效副本,对应区块有效副本减少,会触发复制操作,添加到neededReplications中。而在数据节点撤销一段时间后,因为某种原因又停止撤销了(如手动停止撤销),即数据节点不处于已撤销或正在撤销状态,上面的区块为有效副本了,这样在选择源数据节点前更新副本状态能够避免剩下的复制操作的执行(副本数正常了,没必要复制了)。当然了,对于已经复制的副本,则只能在之后发现超出期望副本数,从而触发多余副本的删除操作。
这样的检查在后面选择目标数据节点时也会执行,同样的道理。
3.2.2 选择目标数据节点
1 | DatanodeDescriptor targets[] = replicator.chooseTarget(fileINode, |
如上,如果目标数据节点没有,则不能复制返回false。
目标数据节点的选择由BlockPlacementPolicy对象replicator的chooseTarget方法完成
传入参数fileINode为对应文件,requiredReplication-numEffectiveReplicas为需要复制的份数也就是要选择的目标数据节点个数。srcNode为前面选择的源数据节点,containingNodes为前面选择出来的包含区块的所有数据节点。
最终会调用BlockPlacementPolicy的同名方法,为抽象方法,实现在BlockPlacementPolicyDefault类中,如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27DatanodeDescriptor[] chooseTarget(int numOfReplicas, DatanodeDescriptor writer,
List<DatanodeDescriptor> chosenNodes, HashMap<Node, Node> excludedNodes, long blocksize) {
...//初始化,要选择节点数调整等
//根据副本总数和机架数计算每个机架上最大可选择节点数
int maxNodesPerRack = (totalNumOfReplicas-1)/clusterMap.getNumOfRacks()+2;
//选择结果初始化为chosenNodes
List<DatanodeDescriptor> results = new ArrayList<DatanodeDescriptor>(chosenNodes);
for (DatanodeDescriptor node:chosenNodes) {//选择前已经存在区块副本的数据节点添加到excludedNodes中,不重复选择
// add localMachine and related nodes to excludedNodes
addToExcludedNodes(node, excludedNodes);
adjustExcludedNodes(excludedNodes, node);
}
if (!clusterMap.contains(writer)) {
writer=null;
}
boolean avoidStaleNodes = (stats != null && stats.shouldAvoidStaleDataNodesForWrite());//是否选择过时的节点
//选择目标节点
DatanodeDescriptor localNode = chooseTarget(numOfReplicas, writer,
excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes);
results.removeAll(chosenNodes);//从结果中移除选择操作之前的节点
//排序结果,形成管道
return getPipeline((writer==null)?localNode:writer, results.toArray(new DatanodeDescriptor[results.size()]));
}
如上,给定源数据节点和目前已经存在区块的数据节点,最多选择numOfReplicas个数据节点,我们这里传入的excludedNodes为null。做了相应的处理后,通过同名方法chooseTarget选择目标节点,需要注意的是根据总的副本数和集群中机架数需要计算一个机架上最大可以选择的节点数maxNodesPerRack。
注意的是,选择目标数据节点前已经存在区块副本的数据节点chosenNodes会添加到excludedNodes中不会重复选择这些数据节点。同时chosenNodes会作为results的初始值,根据这些初始值做出选择,在选择完后从results中删除
3.2.2.1 目标数据节点选择原则
在新的chooseTarget方法中,选择节点时有一下规则:
第一个节点,尽量和源数据节点选在同一个机架上
1
2
3
4
5
6if (numOfResults == 0) {
writer = chooseLocalNode(writer, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes);
if (--numOfReplicas == 0) {
return writer;
}
}如上,选择和源数据节点writer同一个机架上节点,不过要满足不能是excludedNodes中节点(excludedNodes中包括chosenNodes),一个机架上选择的节点数不能超出maxNodesPerRack。选择同一机架上的一个数据节点由chooseLocalNode完成,具体代码不再分析。
第二个节点,必须选择和第一个数据节点不同机架上的另一个节点
1
2
3
4
5
6
7if (numOfResults <= 1) {//小于等于1,等于0的情况前面已经处理,这里处理等于1的情况,即选择第二个节点
//与第一个数据节点(results.get(0))所在机架不同机架上选择一个数据节点,满足excludedNodes和maxNodesPerRack等条件
chooseRemoteRack(1, results.get(0), excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes);
if (--numOfReplicas == 0) {
return writer;
}
}如上,处理results中已经有一个数据节点,选择第二个数据节点的情况。通过chooseRemoteRack选择一个与第一个数据节点机架不同机架上的数据节点,满足excludedNodes和maxNodesPerRack等条件。
- 第三个节点,如果
- 前两个节点在同一机架上,则选择和前两个节点所在机架不同机架上的一个数据节点
- 前两个节点不在同一机架上,如果
- 之前没有存在区块副本的数据节点,选择前results.size()==0,即results中所有节点都是这次选择结果,不包含原来存在的数据节点,则选择和第二个节点同一机架上的一个节点。
因为选择区块复制的目标数据节点时,该区块目前存在的副本数所在数据节点会在选择时添加到results中,根据现存区块副本的数据节点来选择新的数据节点,以防止选择的数据节点与现存数据节点一样而导致原来本来有问题的数据节点又被选择,或者原来数据节点选择复制后存在多个副本等情况。在选择完后,原来的数据节点会从results中移除。 - 之前有存在区块副本的数据节点,选择前results.size()!=0,即前面chosenNodes初始化results,results有初始值,则选择和源数据节点统一机架上的一个节点
代码如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16int numOfResults = results.size();
boolean newBlock = (numOfResults==0);
...
if (numOfResults <= 2) {//小于等于2,0,1前面分析了,因此这里处理等于2即选择第三个数据节点的情况
if (clusterMap.isOnSameRack(results.get(0), results.get(1))) {//第一个和第二个节点在一个机架上
//选择一个和前面两个节点不同机架的节点,满足excludedNodes和maxNodesPerRack
chooseRemoteRack(1, results.get(0), excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes);
} else if (newBlock){//前两个节点机架不同,且results没有初始节点,选择和第二个数据节点(results.get(1))同一机架上的一个数据节点
chooseLocalRack(results.get(1), excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes);
} else {//前两个节点机架不同,且results中有初始节点,选择和源数据节点(writer)同一机架的一个数据节点
chooseLocalRack(writer, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes);
}
if (--numOfReplicas == 0) {
return writer;
}
}
- 之前没有存在区块副本的数据节点,选择前results.size()==0,即results中所有节点都是这次选择结果,不包含原来存在的数据节点,则选择和第二个节点同一机架上的一个节点。
超过3个节点的其他节点,从集群中随机选择
1
chooseRandom(numOfReplicas, NodeBase.ROOT, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes)
如果要选择的副本数超过3个,则剩下的从集群中随机选择,当然要满足excludedNodes和maxNodesPerRack等条件。注意这里选择的是剩下的numOfReplicas个数据节点,前面的都是一次处理一种情况,选择一个节点,选择到一个节点后numOfReplicas减一,因此这里的numOfReplicas为剩下的要选择的数据节点。
3.2.2.2 选择的目标数据节点形成管道(网络拓扑)
如前,通过chooseTarget选择完数据节点后,因为在选择前将之前存在副本的数据节点添加到results作为初始值,选择后要移除。移除后的results为最新选择的数据节点,通过getPipeline方法排序选择结果,形成管道返回,前面方法最后部分如下1
2
3results.removeAll(chosenNodes);//从结果中移除选择操作之前的节点
//排序结果,形成管道
return getPipeline((writer==null)?localNode:writer, results.toArray(new DatanodeDescriptor[results.size()]));
getPipeline同样为BlockPlacementPolicyDefault中的方法,会将选择结果results根据在集群中节点之间的距离进行排序,第一个节点与源数据节点最近,第二个节点为剩下的与第一个节点最近,第三个为剩下的与第二个距离最近,以此类推。
两个节点间的距离由BlockPlacementPolicyDefault中成员clusterMap的getDistance方法计算,clusterMap为NetworkTopology类。
NetworkTopology即网络拓扑,Hadoop中把数据节点形成的网络拓扑看成一棵树,如/datacenter1/rack1/node1,/datacenter1/rack1/node2,分别为数据中心中某一机架上的两个数据节点。
网络拓扑中节点表示为接口org.apache.hadoop.net.Node的实现,DatanodeDescriptor实现了该接口,主要方法如下1
2
3
4
5
6
7public String getNetworkLocation();//获取网络位置,如/rack1/node1
public void setNetworkLocation(String location);//设置网络位置
public String getName();//节点名字
public Node getParent();//节点的父节点
public void setParent(Node parent);//设置父节点
public int getLevel();//节点在树中的层级,根节点的层级为0,根节点子节点层级为1
public void setLevel(int i);//设置在树中层级
计算两个节点的距离直观的即为树中两个节点的距离,例如下图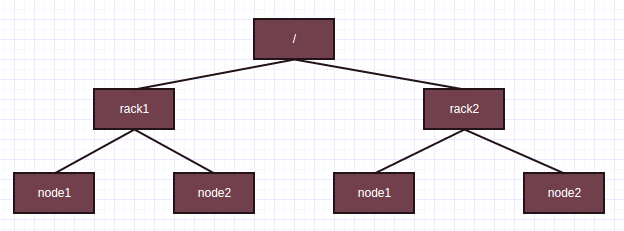
/rack1/node1到/rack1/node2之间距离为2,rack1/node1到rack2/node1之间距离为4
前面第三个节点选择时,isOnSameRack判断是否为一个机架也是根据网络拓扑来的,两个节点的父节点如果相同,则在一个机架上。
那么节点的网络位置是怎么来的呢?由DNSToSwitchMapping接口提供DNS名字或者IP地址到网络拓扑中的网络位置转换,该接口被HDFS和MapReduce等组件使用1
2
3public interface DNSToSwitchMapping {
public List<String> resolve(List<String> names);
}
如上,只有一个方法resolve,将保存节点名字或IP地址的参数names转换成对应的网络位置。
配置项topology.node.switch.mapping.impl用于指定它的一个实现,目前其实现有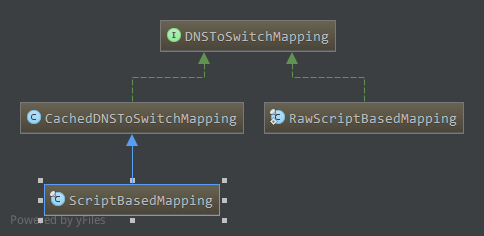
ScriptBasedMapping类,可以通过运行一个Shell脚本,完成转换。
没有配置的情况下,DatanodeDescriptor缺省网络位置为/default-rack。
有了节点间的距离计算,对results的排序就比较好处理了,首先查找与源数据节点writer最近的一个节点排在results的第一个节点位置,然后查找与当前第一个节点距离最近的数据节点排在第二个节点位置,以此类推,代码不再贴出。这样,建立数据流管道时,每个节点到直接下游节点的网络距离是最短的,减少网络损耗。
3.2.2.3 ScriptBasedMapping
DNSToSwitchMapping默认实现使用ScriptBasedMapping, ScriptBasedMapping继承自CachedDNSToSwitchMapping,可对解析结果进行缓冲。
CacheDNSToSwitchMapping成员如下1
2private Map<String, String> cache = new ConcurrentHashMap<String, String>();
protected DNSToSwitchMapping rawMapping;
如上,cache缓冲了解析的结果,键为主机名(或IP),值为解析结果网络位置,rawMapping为底层的DNSToSwitchMapping实现,构造如下1
2
3public CachedDNSToSwitchMapping(DNSToSwitchMapping rawMapping) {
this.rawMapping = rawMapping;
}
ScriptBasedMapping继承自CacheDNSToSwitchMapping,构造如下1
2
3
4
5
6
7
8
9
10
11public ScriptBasedMapping(Configuration conf) {
this();
setConf(conf);
}
public ScriptBasedMapping() {
super(new RawScriptBasedMapping());
}
public void setConf(Configuration conf) {
((RawScriptBasedMapping)rawMapping).setConf(conf);
}
如上,创建DNSToSwitchMapping实现类RawScriptBasedMapping构造父类,RawScriptBasedMapping为ScriptBasedMapping的内部类,RawScriptBasedMapping成员如下1
2
3private String scriptName;
private Configuration conf;
private int maxArgs; //max hostnames per call of the script
如上,RawScriptBasedMapping使用Shell脚本对主机名进行解析,scriptName保存脚本名,maxArgs为脚本每次能处理的最大主机名数目
创建RawScriptBasedMapping后进行配置,配置也是使用RawScriptBasedMapping的setConf方法如下1
2
3
4
5public void setConf (Configuration conf) {
this.scriptName = conf.get(SCRIPT_FILENAME_KEY);
this.maxArgs = conf.getInt(SCRIPT_ARG_COUNT_KEY, DEFAULT_ARG_COUNT);
this.conf = conf;
}
如上,读取配置项topology.script.file.name初始化scriptName,topology.script.number.args初始化maxArgs。
然后看ScriptBasedMapping解析函数resolve,直接继承CachedDNSToSwitchMapping的resolve函数,如下1
2
3
4
5
6
7
8
9
10
11
12
13public List<String> resolve(List<String> names) {
// normalize all input names to be in the form of IP addresses
//将所有的输入正规化为IP地址的形式
names = NetUtils.normalizeHostNames(names);
List <String> result = new ArrayList<String>(names.size());
if (names.isEmpty()) {//没有要解析的主机
return result;
}
List<String> uncachedHosts = this.getUncachedHosts(names);//不在cache中的主机,即解析后需要添加的
List<String> resolvedHosts = rawMapping.resolve(uncachedHosts);//通过RawDNSToSwitchMapping进行解析
this.cacheResolvedHosts(uncachedHosts, resolvedHosts);//缓存到cache中
return this.getCachedHosts(names);
}
如上,会调用底层的DNSToSwitchMapping实现,即RawDNSToSwitchMapping对象的resolve函数进行解析,解析结果如果不在缓存cache中添加到cache中,注意的是会将所有的输入正规化为IP地址的形式,因此Shell脚本处理的输入为IP地址。RawDNSToSwitchMapping中的resolve方法如下,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31public List<String> resolve(List<String> names) {
List <String> m = new ArrayList<String>(names.size());
if (names.isEmpty()) {//要解析的主机名为空,返回
return m;
}
if (scriptName == null) {//脚本名不存在,即没有配置脚本,所有的主机解析成/default-rack
for (int i = 0; i < names.size(); i++) {
m.add(NetworkTopology.DEFAULT_RACK);
}
return m;
}
String output = runResolveCommand(names);//循环调用脚本解析,一次解析maxArgs个主机名
if (output != null) {
StringTokenizer allSwitchInfo = new StringTokenizer(output);
while (allSwitchInfo.hasMoreTokens()) {
String switchInfo = allSwitchInfo.nextToken();
m.add(switchInfo);
}
if (m.size() != names.size()) {//脚本返回的解析结果与输入参数不对应
LOG.warn("Script " + scriptName + " returned "
+ Integer.toString(m.size()) + " values when "
+ Integer.toString(names.size()) + " were expected.");
return null;
}
} else {
return null;
}
return m;
}
如上,如果没有配置脚本,则所有的主机名被解析成/default-rack,否则通过runResolveCommand对所有的主机名进行解析。
runResolveCommand这里不贴出代码了,会循环进行解析,每次解析maxArgs个主机名,解析时通过创建ShellCommandExecutor对象执行Shell脚本,输入的参数保存在数组中,依次为脚本名和maxArgs个输入主机名,因此脚本需要对若干个输入进行解析(输入为IP地址),解析结果输出,输出的项应该和输入项一致,输出结果之间可以通过空格,制表符,回车符,换行符,换页符进行分隔。
3.2.3 添加到源数据节点的待复制队列
到这里目标节点选择完成,回到computeReplicationWorkForBlock中,接下来进行相关检查,将区块和目标数据节点等信息添加到源数据节点的replicateBlocks中,更新pendingReplications1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23synchronized (this) {
synchronized (neededReplications) {
...//如前重新检查区块元信息,如果区块对应文件不存在或者正在写则不能复制,从neededReplications中移除记录,并返回false
...//如前重新检查副本数是否满足了期望值,如果满足了则不需要进行复制,从neededReplications中移除记录,返回false
//添加区块到源数据节点的待复制列表replicateBlocks中,通知指定目标数据节点
srcNode.addBlockToBeReplicated(block, targets);
for (DatanodeDescriptor dn : targets) {
dn.incBlocksScheduled();
}
//更新区块在pendingReplications中的记录,原来没记录则新增该区块正在复制副本数为targets长度,原来有记录则增加正在复制的副本数
pendingReplications.increment(block, targets.length);
NameNode.stateChangeLog.debug("BLOCK* " + block + " is moved from neededReplications to pendingReplications");
//如果本次添加到源数据节点后,使得正在复制的副本数加上有效副本数达到了期望值,则从neededReplications中移除记录
if(numEffectiveReplicas + targets.length >= requiredReplication) {
neededReplications.remove(block, priority); // remove from neededReplications
replIndex--;
}
}
}
如上,首先重新检查相关元数据,这里需要重新检查是因为在选择目标数据节点前释放了相关锁,选择目标过程中不使用全局锁,因为在选择目标数据节点过程中持有锁代价太高,如下为代码中不使用锁的注释1
2
3// choose replication targets: NOT HOLDING THE GLOBAL LOCK
// It is costly to extract the filename for which chooseTargets is called,
// so for now we pass in the Inode itself.
因此重新获取锁后要进行检查。相关检查后,添加区块到源数据节点的待复制区块队列replicateBlocks中,复制的目标数据节点为targets,如前面对replicateBlocks的介绍,根据Block和targets创建BlockTargetPair对象,添加到队列中。
然后更新pendingReplications,因为新增了正在复制的副本数。如果本次新增后正在复制的副本数和之前有效副本数(集群中存储的)达到了期望值,则从neededReplications中移除。
这样复制操作完成,可以返回true了。等待源数据节点下一次心跳到来,FSNamesystem在处理心跳时发现源数据节点有待复制的区块,发送相应的区块复制命令,执行复制。
4. computeInvalidateWork删除操作
1 | int computeInvalidateWork(int nodesToProcess) { |
如上,传入参数nodesToProcess为一次处理的节点个数,默认为所有数据节点的32%,根据recentInvalidateSets中可以处理的数据节点进行调节。
然后随机选择nodesToProcess个nodesToProcess个数据节点,对每一个数据节点通过invalidateWorkForOneNode进行处理
4.1 invalidateWorkForOneNode
1 | private int invalidateWorkForOneNode(String nodeId) { |
如上,每个数据节点每次能个处理的待删除区块最多为blockInvalidateLimit,为FSNamesystem的成员,默认100。
进行相关检查后,从recentInvalidateSets中数据节点的待删除区块集合中添加最多blockInvalidateLimit个区块记录,并且从recentInvalidateSets中移除添加的记录。
添加完后,相应的区块记录从recentInvalidateSets中移除了,如果此时该数据节点没有待删除区块,都被处理完了,则同时移除该数据节点在recentInvalidateSets中的记录。
最终将blocksToInvalidate中添加的区块集合添加到数据节点的待删除列表invalidateBlocks中。如前面分析,invalidateBlocks为该数据节点上待删除区块,在下次心跳到来时,如果发现invalidateBlocks中有区块,则会向该数据节点发送区块删除命令,执行删除。
到这里,ReplicationMonitor的复制和删除操作都分析完了,删除操作相对复制操作简单,因为不需要选择源数据节点和目标数据节点。