Hadoop版本:Hadoop-1.2.1
参考:《Hadoop技术内幕-深入解析Hadoop Common和HDFS架构设计与实现原理》
在DataNode启动时,会创建流服务Socket,绑定本地地址,然后开启DataXceiverServer线程接收到来的流操作连接请求。
DataXceiverServer成员属性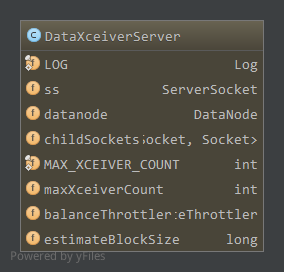
ss,流服务Socketdatanode,所属DataNodechildSockets,accept的Socket,即现在服务的连接maxXceiverCount,最大xceivers数目,即最大连接数,防止占用太多资源,每个连接都是一个线程,默认256。balanceThrottler,带宽均衡器,限制区块传输的数量和使用的带宽estimateBlockSize,预估的区块大小,默认64MB
DataXceiverServer线程的主程序如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public void run() {
while (datanode.shouldRun) {
try {
Socket s = ss.accept();//accept到来的连接
s.setTcpNoDelay(true);//关闭Nagle算法
//创建DataXceiver线程服务该连接上的操作
new Daemon(datanode.threadGroup, new DataXceiver(s, datanode, this)).start();
}...//异常处理
}
try {
ss.close();
} catch (IOException ie) {
LOG.warn(datanode.dnRegistration + ":DataXceiveServer: Close exception due to: "
+ StringUtils.stringifyException(ie));
}
LOG.info("Exiting DataXceiveServer");
}
如上,对于到来的连接,accept一个Socket,将这个Socket封装在DataXceiver线程中服务到来的操作请求,线程所属的线程组与DataXceiverServer一样,还是DataNode中的那个线程组。
accept中的异常,涉及到DataNode的关闭,等待后面分析。在DataXceiverServer关闭时,关闭流服务的Socket。
DataXceiver成员属性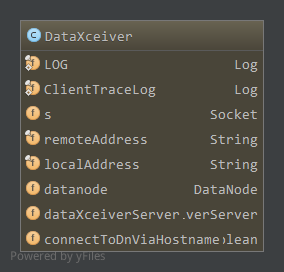
s,连接的Socket,通过DataXceiverServer的Socket accept得到remoteAddress,对端的地址localAddress,本地地址datanode,所属的DataNodedataXceiverServer,所属的DataXceiverServer
DataXceiver线程的主程序如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60public void run() {
DataInputStream in=null;
try {
in = new DataInputStream(new BufferedInputStream(NetUtils.getInputStream(s),SMALL_BUFFER_SIZE));
short version = in.readShort();//读取对端DataTransferProtocol的版本号
if ( version != DataTransferProtocol.DATA_TRANSFER_VERSION ) {
throw new IOException( "Version Mismatch" );
}
boolean local = s.getInetAddress().equals(s.getLocalAddress());
byte op = in.readByte();//读取操作码
//当前连接数(xceiver线程数)不能超过限制
int curXceiverCount = datanode.getXceiverCount();
if (curXceiverCount > dataXceiverServer.maxXceiverCount) {
throw new IOException("xceiverCount " + curXceiverCount
+ " exceeds the limit of concurrent xcievers "
+ dataXceiverServer.maxXceiverCount);
}
long startTime = DataNode.now();
switch ( op ) {
case DataTransferProtocol.OP_READ_BLOCK://读请求
readBlock( in );
datanode.myMetrics.addReadBlockOp(DataNode.now() - startTime);
if (local)
datanode.myMetrics.incrReadsFromLocalClient();
else
datanode.myMetrics.incrReadsFromRemoteClient();
break;
case DataTransferProtocol.OP_WRITE_BLOCK://写请求
writeBlock( in );
datanode.myMetrics.addWriteBlockOp(DataNode.now() - startTime);
if (local)
datanode.myMetrics.incrWritesFromLocalClient();
else
datanode.myMetrics.incrWritesFromRemoteClient();
break;
case DataTransferProtocol.OP_REPLACE_BLOCK: //替换请求
replaceBlock(in);
datanode.myMetrics.addReplaceBlockOp(DataNode.now() - startTime);
break;
case DataTransferProtocol.OP_COPY_BLOCK://复制请求
copyBlock(in);
datanode.myMetrics.addCopyBlockOp(DataNode.now() - startTime);
break;
case DataTransferProtocol.OP_BLOCK_CHECKSUM://读取校验信息请求
getBlockChecksum(in);
datanode.myMetrics.addBlockChecksumOp(DataNode.now() - startTime);
break;
default:
throw new IOException("Unknown opcode " + op + " in data stream");
}
} catch (Throwable t) {
LOG.error(datanode.dnRegistration + ":DataXceiver",t);
} finally {
LOG.debug(datanode.dnRegistration + ":Number of active connections is: "
+ datanode.getXceiverCount());
IOUtils.closeStream(in);
IOUtils.closeSocket(s);
dataXceiverServer.childSockets.remove(s);
}
}
如上,在HDFS流接口中分析过了有5中流操作,写数据块,读数据块,替换数据块,复制数据块,读取数据块的校验信息。每种操作的请求都会包含DataTransferProtocol的版本号以及操作对应的操作码。
因此通过socket获取输入流后首先读取版本号进行验证,然后读取操作码,根据不同的操作码执行不同的操作。
- 写数据块由
writeBlock(in)负责 - 读数据由
readBlock(in)负责 - 数据块替换由
replaceBlock(in)负责 - 数据块复制由
copyBlock(in)负责 - 获取数据块校验信息由
getBlockChecksum(in)负责
接下来分析各个操作的实现。
限于篇幅,本文分析写数据块的实现,后面的4中操作见下篇
写数据块
写数据通过writeBlock实现,如HDFS流接口中分析,写数据时会建立数据流管道。写请求后会等待应答,正常时数据流管道建立完成,才开始接收数据。
writeBlock代码比较长,根据流程分段分析
1. 读写请求帧数据
首先是读取写请求帧数据1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21Block block = new Block(in.readLong(), dataXceiverServer.estimateBlockSize, in.readLong());
int pipelineSize = in.readInt(); // num of datanodes in entire pipeline
boolean isRecovery = in.readBoolean(); // is this part of recovery?
String client = Text.readString(in); // working on behalf of this client
boolean hasSrcDataNode = in.readBoolean(); // is src node info present
if (hasSrcDataNode) {
srcDataNode = new DatanodeInfo();
srcDataNode.readFields(in);
}
int numTargets = in.readInt();
if (numTargets < 0) {
throw new IOException("Mislabelled incoming datastream.");
}
DatanodeInfo targets[] = new DatanodeInfo[numTargets];
for (int i = 0; i < targets.length; i++) {
DatanodeInfo tmp = new DatanodeInfo();
tmp.readFields(in);
targets[i] = tmp;
}
Token<BlockTokenIdentifier> accessToken = new Token<BlockTokenIdentifier>();
accessToken.readFields(in);
如上,写请求帧格式见HDFS流接口client不为空时为Client的写操作,否则为NameNode写指令或区块均衡器操作的写。numTargets大于0时,当前DataNode不是数据流管道的最后一个节点,需要建立到target[0]的连接并发送数据。
2. 创建BlockReceiver对象
接收数据由BlockReceiver负责,构造BlockReceiver对象1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41blockReceiver = new BlockReceiver(block, in, s.getRemoteSocketAddress().toString(),
s.getLocalSocketAddress().toString(), isRecovery, client, srcDataNode, datanode)
BlockReceiver(Block block, DataInputStream in, String inAddr,
String myAddr, boolean isRecovery, String clientName,
DatanodeInfo srcDataNode, DataNode datanode) throws IOException {
try{
this.block = block;
this.in = in;
this.inAddr = inAddr;
this.myAddr = myAddr;
this.isRecovery = isRecovery;
this.clientName = clientName;
this.offsetInBlock = 0;
this.srcDataNode = srcDataNode;
this.datanode = datanode;
this.checksum = DataChecksum.newDataChecksum(in);
this.bytesPerChecksum = checksum.getBytesPerChecksum();
this.checksumSize = checksum.getChecksumSize();
this.dropCacheBehindWrites = datanode.shouldDropCacheBehindWrites();
this.syncBehindWrites = datanode.shouldSyncBehindWrites();
//追加或创建本地区块文件和校验文件,创建文件输出流
streams = datanode.data.writeToBlock(block, isRecovery, clientName == null || clientName.length() == 0);
this.finalized = false;
if (streams != null) {
this.out = streams.dataOut;
this.cout = streams.checksumOut;
if (out instanceof FileOutputStream) {
this.outFd = ((FileOutputStream) out).getFD();
} else {
LOG.warn("Could not get file descriptor for outputstream of class " + out.getClass());
}
this.checksumOut = new DataOutputStream(new BufferedOutputStream(streams.checksumOut, SMALL_BUFFER_SIZE));
//如果是追加操作,则从区块扫描器中移除
if (datanode.blockScanner != null && isRecovery) {
datanode.blockScanner.deleteBlock(block);
}
}
}
...//异常处理
}
如上,初始化BlockReceiver中基本成员后,会通过DataNode FSDataset对象的writeToBlock打开要追加的区块文件或者创建新的区块文件以及校验文件,打开文件的输出流对象。如果对应的是追加操作,因为会改变现有区块,要从区块扫描器中移除。
其他成员这里不再列出。
2.1 FSDataset.writeToBlock
writeToBlock如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87public BlockWriteStreams writeToBlock(Block b, boolean isRecovery, boolean replicationRequest) throws IOException {
if (isValidBlock(b)) {//如果文件已经存在,则只能是修复操作,如追加
if (!isRecovery) {
throw new BlockAlreadyExistsException("Block " + b + " is valid, and cannot be written to.");
}
//如果存在与该区块文件相关的硬链接,将文件与硬链接分离
detachBlock(b, 1);
}
long blockSize = b.getNumBytes();
File f = null;
List<Thread> threads = null;
synchronized (this) {
ActiveFile activeFile = ongoingCreates.get(b);
if (activeFile != null) {//已经有其他线程创建了区块
f = activeFile.file;
threads = activeFile.threads;
if (!isRecovery) {//此时只允许恢复相关的操作
throw new BlockAlreadyExistsException("Block " + b +
" has already been started (though not completed), and thus cannot be created.");
} else {
for (Thread thread:threads) {//中断其他创建线程
thread.interrupt();
}
}
ongoingCreates.remove(b);
}
FSVolume v = null;
if (!isRecovery) {//非恢复操作
v = volumes.getNextVolume(blockSize);//获取下一个可用存储目录
f = createTmpFile(v, b, replicationRequest);//在存储目录中创建临时区块文件
} else if (f != null) {//恢复操作,文件已经创建了重用打开的文件
DataNode.LOG.info("Reopen already-open Block for append " + b);
v = volumeMap.get(b).getVolume();
volumeMap.put(b, new DatanodeBlockInfo(v, f));
} else {恢复操作,重新打开区块文件追加,打开的文件要放到临时目录中
DataNode.LOG.info("Reopen for append " + b);
v = volumeMap.get(b).getVolume();
f = createTmpFile(v, b, replicationRequest);//blocksBeingWritten或tmp目录中
File blkfile = getBlockFile(b);
File oldmeta = getMetaFile(b);
File newmeta = getMetaFile(f, b);
DataNode.LOG.debug("Renaming " + oldmeta + " to " + newmeta);
if (!oldmeta.renameTo(newmeta)) {//原来的校验文件重命名到临时目录中
throw new IOException("Block " + b + " reopen failed. " +
" Unable to move meta file " + oldmeta + " to tmp dir " + newmeta);
}
if (!blkfile.renameTo(f)) {//区块文件重命名到临时目录中
if (!f.delete()) {
throw new IOException(b + " reopen failed. " + " Unable to remove file " + f);
}
if (!blkfile.renameTo(f)) {
throw new IOException(b + " reopen failed. " + " Unable to move block file " + blkfile + " to tmp dir " + f);
}
}
}
if (f == null) {
DataNode.LOG.warn(b + " reopen failed. Unable to locate tmp file");
throw new IOException("Block " + b + " reopen failed " + " Unable to locate tmp file.");
}
//更新volumeMap和ongoingCreates
// If this is a replication request, then this is not a permanent
// block yet, it could get removed if the datanode restarts. If this
// is a write or append request, then it is a valid block.
if (replicationRequest) {
volumeMap.put(b, new DatanodeBlockInfo(v));
} else {
volumeMap.put(b, new DatanodeBlockInfo(v, f));
}
ongoingCreates.put(b, new ActiveFile(f, threads));
}
try {//等待之前创建线程结束
if (threads != null) {
for (Thread thread:threads) {
thread.join();
}
}
} catch (InterruptedException e) {
throw new IOException("Recovery waiting for thread interrupted.");
}
File metafile = getMetaFile(f, b);
DataNode.LOG.debug("writeTo blockfile is " + f + " of size " + f.length());
DataNode.LOG.debug("writeTo metafile is " + metafile + " of size " + metafile.length());
return createBlockWriteStreams( f , metafile);//创建区块文件和校验文件对应的输出流
}
如上,如果区块文件已经存在,则只允许恢复操作如对区块的追加,不能创建同样的区块文件,此时如果存在硬链接需要分离,这样回滚到以前的版本时,对应的区块文件为原来的未更改的区块文件。
分离操作通过detachBlock完成
2.1.1 FSDataset.detach
1 | private void detachFile(File file, Block b) throws IOException { |
如上,省去了FSDataset.detach处理的中间过程,上面为DatanodeBlockInfo中的detachFile方法,在FSDataset.detach中会找到文件对应的校验文件,如果文件或校验文件需要detach,则会对文件或校验文件调用该方法。
总的来说,主要逻辑为:
如果区块b对应文件或者校验文件的硬连接大于1,即存在硬链接,将区块b对应的文件或校验文件和文件对应的硬链接分离。分离时,在detach目录下创建与待分离的文件名字一样的文件,然后将原来数据拷贝到detach目录下的文件中,最后重命名detach目录下的文件为源文件,此时文件的inode号与原来的inode号不一样,达到与其他硬链接文件分离的目的。
对于恢复操作,如果文件已经打开直接重用即可,否则重新打开区块文件,在临时目录中创建临时文件,重命名区块文件和校验文件到临时目录,临时目录根据是否为复制操作还是Client的写操作可能为ongoingCreates或tmp目录,具体逻辑在createTmpFile中
2.1.2 FSDataset.createTmpFile
1 | synchronized File createTmpFile( FSVolume vol, Block blk, boolean replicationRequest) throws IOException { |
如上,如果是复制请求对应的为非Client写数据,则临时目录为tmp,而Client写数据使用的临时目录为blocksBeingWritten。
如果不是恢复操作,直接在临时目录中创建相应的临时文件。不管是否为恢复操作,最终都要将区块对应信息添加到ongoingCreates和volumeMap中。
临时目录的文件只有在操作完成(数据写完)后才会提交到current目录中。
以上操作完成后,打开临时文件(区块文件和校验文件)的输出流,构造BlockWriteStreams对象。
回到BlockReceiver的构造方法中,BlockReceiver的streams成员保存着接收区块数据和校验数据的文件输出流,checksumOut成员将校验文件输出流封装成DataOutputStream。
再回到DataXceiver的writeBlock方法中,BlockReceiver对象构造完后,如果本DataNode之后还有下游数据节点,需要建立到下游节点的连接,同样的发送区块写请求
3. 建立数据流管道
1 | if (targets.length > 0) { |
如上,连接到下游节点,注意的有以下几点:
- 因为要建立数据流管道,数据流管道上的每个连接都对应可能连接超时,读超时,写超时,因此需要调整DataNode的相应超时时间,如果当前DataNode后面还有n个DataNode,则对于连接和读操作后面的每一个连接允许超时为3s,而对于写操作每个连接允许超时为5s。
- 连接到下游节点即targets[0]后,发送区块写请求,要减少targets节点,到管道上最后一个节点时,其接收到的targets数组长度为0。
- 如果是客户端写数据,向下游节点发送完区块写请求后,等待接收下游节点的写请求应答,包括状态和第一个联系不上的节点,接收到应答后,发送写请求响应到上游节点。
也就是说,数据流管道上的最后一个节点无需往下游节点发送写请求,则直接往上游节点发送写请求应答,上游节点收到下游节点应答后继续往上游发送应答,直到Client,一切正常数据流管道建立。
而如果某个节点连接到下游节点超时,或者说从下游节点接收写请求应答超时,则该节点的第一个联系不上的节点即为下游节点,此时往上游节点发送写请求应答,对应的状态为 OP_STATUS_ERROR,并发送第一个联系不上的节点即下游节点,抛出异常,终止后面的操作,此时数据流管道建立失败。
往上游节点发送完写请求响应之后,便等待读取数据,如果实际数据流管道没有建立成功(如某节点接收到下游节点的响应为OP_STATUS_ERROR),则该节点会在等待读取数据过程中超时。
4. 接收数据,发送到下游节点
1 | try{ |
如上,通过BlockReceiver的receiveBlock接收区块数据,接收完后,如果不是客户端写,则添加到receiveBlockList中,在DataNode的offerService中通知NameNode接收到新的区块数据,而Client写的提交工作由PacketResponder负责。同时添加区块到区块扫描器中,定期验证是否出错。
在整个过程中如果出现异常,抛出,写操作请求处理失败。最终会关闭所有打开的流。
4.1 receiveBlock
receiveBlock实现如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45void receiveBlock(
DataOutputStream mirrOut, // output to next datanode
DataInputStream mirrIn, // input from next datanode
DataOutputStream replyOut, // output to previous datanode
String mirrAddr, DataTransferThrottler throttlerArg,
int numTargets) throws IOException {
mirrorOut = mirrOut;
mirrorAddr = mirrAddr;
throttler = throttlerArg;
try {
if (!finalized) {//写校验文件头,包括2个字节的版本(1),1个字节的校验类型,4个字节的校验块大小
BlockMetadataHeader.writeHeader(checksumOut, checksum);
}
if (clientName.length() > 0) {//如果是Client写,创建PacketResponder处理响应
responder = new Daemon(datanode.threadGroup,
new PacketResponder(this, block, mirrIn, replyOut, numTargets, Thread.currentThread()));
responder.start();
}
while (receivePacket() > 0) {}//循环接收包,写到本地文件和下游节点
if (mirrorOut != null) {
try {
mirrorOut.writeInt(0); // mark the end of the block
mirrorOut.flush();
} catch (IOException e) {
handleMirrorOutError(e);
}
}
// wait for all outstanding packet responses. And then
// indicate responder to gracefully shutdown.
if (responder != null) {
((PacketResponder)responder.getRunnable()).close();
}
//非客户端写,提交临时文件到current中
if (clientName.length() == 0) {
//关闭区块文件和校验文件
close();
block.setNumBytes(offsetInBlock);
datanode.data.finalizeBlock(block);
datanode.myMetrics.incrBlocksWritten();
}
}...//异常处理和最后的清理工作
}
如上,先写校验文件头,包括版本号(1),校验类型,校验块大小。如果是客户端写操作,创建PacketResponder线程并启动等待处理响应,实际的接收上游数据写到临时文件以及发送到下游节点是通过receivePacket完成的,receivePacket接收一个包并发送到下游节点,循环接收直到接受完。
先看PacketResponder
4.2 PacketResponder
PacketResponder线程成员如下:1
2
3
4
5
6
7
8private LinkedList<Packet> ackQueue = new LinkedList<Packet>();//等待接收下游ACK的包
private volatile boolean running = true;
private Block block;
DataInputStream mirrorIn; //读取下游节点数据的输入流
DataOutputStream replyOut; //往上游节点写响应的输出流
private int numTargets; //下游节点数目包括本身
private BlockReceiver receiver; //所属的区块接收器
private Thread receiverThread; //创建该线程的线程,为区块接收器所属线程
如上,创建PacketResponder线程1
2
3
4
5
6
7
8
9PacketResponder(BlockReceiver receiver, Block b, DataInputStream in,
DataOutputStream out, int numTargets, Thread receiverThread) {
this.receiver = receiver;
this.block = b;
mirrorIn = in;
replyOut = out;
this.numTargets = numTargets;
this.receiverThread = receiverThread;
}
此时,ackQueue队列为空,会在线程主程序中等待,当发送一个包到下游节点时,会添加到ackQueue中,然后在线程中等待接收该包的ACK。接收ACK逻辑后面分析。
通过receivePacket接收一个包并发送到下游节点
在receivePacket中,首先通过readNextPacket读取一个完整的包到BlockReceiver的成员bufByteBuffer中1
2
3
4int payloadLen = readNextPacket();
if (payloadLen <= 0) {
return payloadLen;
}
4.3 readNextPacket
readNextPacket实现如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60private int readNextPacket() throws IOException {
if (buf == null) {//分配缓冲区,最大为数据节点writePacketSize,调整能够接收整个包的大小
int chunkSize = bytesPerChecksum + checksumSize;
int chunksPerPacket = (datanode.writePacketSize - DataNode.PKT_HEADER_LEN -
SIZE_OF_INTEGER + chunkSize - 1)/chunkSize;
buf = ByteBuffer.allocate(DataNode.PKT_HEADER_LEN + SIZE_OF_INTEGER +
Math.max(chunksPerPacket, 1) * chunkSize);
buf.limit(0);
}
if (bufRead > buf.limit()) {
buf.limit(bufRead);
}
while (buf.remaining() < SIZE_OF_INTEGER) {//缓冲区中没有足够剩余数据要读取数据
if (buf.position() > 0) {//当前缓冲区position大于0,将可用数据移到最前面重用缓冲区
shiftBufData();
}
readToBuf(-1);//尝试读满缓冲区
}
//到这里一般有完整的包的数据了,至少有一个int值
buf.mark();
int payloadLen = buf.getInt();//读取payloadLen
buf.reset();
if (payloadLen == 0) {//接收完
buf.limit(buf.position() + SIZE_OF_INTEGER);
return 0;
}
// check corrupt values for pktLen, 100MB upper limit should be ok?
if (payloadLen < 0 || payloadLen > (100*1024*1024)) {
throw new IOException("Incorrect value for packet payload : " + payloadLen);
}
int pktSize = payloadLen + DataNode.PKT_HEADER_LEN;//包大小
if (buf.remaining() < pktSize) {//剩余可用数据不足一个包的大小,继续读取,需要的话扩充缓冲区
int toRead = pktSize - buf.remaining();//要读的数据
int spaceLeft = buf.capacity() - buf.limit();//缓冲区剩余空间
if (toRead > spaceLeft && buf.position() > 0) {//剩余空间不足且position大于0,将可用数据移到缓冲区最前端
shiftBufData();
spaceLeft = buf.capacity() - buf.limit();
}
if (toRead > spaceLeft) {//如果空间还是不足,重新分配缓冲区,拷贝原来的数据到新缓冲区
byte oldBuf[] = buf.array();
int toCopy = buf.limit();
buf = ByteBuffer.allocate(toCopy + toRead);
System.arraycopy(oldBuf, 0, buf.array(), 0, toCopy);
buf.limit(toCopy);
}
//至此缓冲区空间足够,读取数据,读满缓冲区
while (toRead > 0) {
toRead -= readToBuf(toRead);
}
}
if (buf.remaining() > pktSize) {//调整limit的值
buf.limit(buf.position() + pktSize);
}
if (pktSize > maxPacketReadLen) {
maxPacketReadLen = pktSize;
}
return payloadLen;
}
如上,如果还没分配缓冲区,则分配预估大小的缓冲区,该值为DataNode的成员writePacketSize,默认64KB,调整到能够接收整个包的大小。
如果缓冲区中剩余至少4个字节的数据,这里4个字节是因为发送的包头第一个字段4个字节为有效负载长度,且如果发送结束,对端会发送一个4个字节的0标识,因此根据开始的4个字节能够判断是否读取结束。而如果缓冲区剩余数据不足4个字节,则需要读取数据,先将剩余数据移到缓冲区最前面,重用缓冲区,然后尝试读满整个缓冲区。
若还未结束是一个正常包,则根据负载长度和固定长度的包头算出该包的大小,如果缓冲区剩余数据不够该包大小,需要继续读取数据。读取时,如果空间不足,先将有效数据移到缓冲区最开始处,如果剩余空间还是不足,则分配新的缓冲区,将原来的剩余有效数据拷贝到新缓冲区。最终循环读取直到读满整个缓冲区。
通过readNextPacket读取了整个包数据后,读取包头,写数据的包格式和读数据的包格式一样,见HDFS流接口1
2
3
4
5
6
7buf.mark();
buf.getInt(); //负载长度
offsetInBlock = buf.getLong(); //在区块中的偏移量
long seqno = buf.getLong(); //包序号
boolean lastPacketInBlock = (buf.get() != 0);//是否为最后一个包
int endOfHeader = buf.position();//包头结束位置
buf.reset();
然后根据发送过来的区块中偏移量offsetInBlock将临时文件输出流定位到该偏移量处1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36setBlockPosition(offsetInBlock);
private void setBlockPosition(long offsetInBlock) throws IOException {
if (finalized) {
if (!isRecovery) {
throw new IOException(...);
}
if (offsetInBlock > datanode.data.getLength(block)) {
throw new IOException(...);
}
return;
}
if (datanode.data.getChannelPosition(block, streams) == offsetInBlock) {//当前流位置刚好处于要求位置
return;
}
//计算校验文件中的偏移量
long offsetInChecksum = BlockMetadataHeader.getHeaderSize() + offsetInBlock / bytesPerChecksum * checksumSize;
//输出流数据刷新到文件
if (out != null) {
out.flush();
}
if (checksumOut != null) {
checksumOut.flush();
}
//如果是一个局部的块,需要验证现存的局部块数据是否正确
if (offsetInBlock % bytesPerChecksum != 0) {
...
//读取局部块数据计算校验和,与校验文件中对应的校验和比较看是否正确
computePartialChunkCrc(offsetInBlock, offsetInChecksum, bytesPerChecksum);
}
...
//设置文件流的位置
datanode.data.setChannelPosition(block, streams, offsetInBlock, offsetInChecksum);
}
如上,值得注意的是,如果偏移量不是数据块的开始处,是个局部数据块,即本地保存了该数据块的部分数据,现在接收到了剩余部分数据,需要通过computePartialChunkCrc计算本地校验数据的校验和,计算的校验和保存在BlockReceiver的成员partialCrc中,然后与校验文件中校验和进行验证,代码不贴出来了。通过setChannelPosition定位到区块文件offsetInBlock,校验文件offsetInChecksum处。
文件输出流定位到指定位置了,接下来便是写操作以及向下游节点的数据发送操作
4.4 发送到下游节点
首先发送到下游节点1
2
3
4
5
6
7
8if (mirrorOut != null && !mirrorError) {
try {
mirrorOut.write(buf.array(), buf.position(), buf.remaining());
mirrorOut.flush();
} catch (IOException e) {
handleMirrorOutError(e);
}
}
4.5 写数据到本地文件
然后写数据到本地文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52buf.position(endOfHeader);//定位到有效负载
int len = buf.getInt();//数据长度
...//len<0异常处理
if (len == 0) {
LOG.debug("Receiving empty packet for " + block);
} else {
offsetInBlock += len;
//根据数据长度计算校验和长度
int checksumLen = ((len + bytesPerChecksum - 1)/bytesPerChecksum)* checksumSize;
if ( buf.remaining() != (checksumLen + len)) {
throw new IOException("Data remaining in packet does not match "+"sum of checksumLen and dataLen");
}
int checksumOff = buf.position();//校验和数据偏移量
int dataOff = checksumOff + checksumLen;//数据偏移量
byte pktBuf[] = buf.array();//转换成字节数组
buf.position(buf.limit());//接下来对字节数组操作,不会改变position的值,因此这里先设置
//如果不是Client写数据,则每个接收到数据的DataNode要验证,否则只有数据流管道最后一个节点进行验证
if (mirrorOut == null || clientName.length() == 0) {
verifyChunks(pktBuf, dataOff, len, pktBuf, checksumOff);
}
try {
if (!finalized) {
//数据写到临时文件中
out.write(pktBuf, dataOff, len);
//partialCrc不为null,对应为局部块数据
if (partialCrc != null) {
if (len > bytesPerChecksum) {//局部块时,包中只有局部块剩余数据
throw new IOException("Got wrong length during writeBlock(" +
block + ") from " + inAddr + " " + "A packet can have only one partial chunk."+
" len = " + len + " bytesPerChecksum " + bytesPerChecksum);
}
partialCrc.update(pktBuf, dataOff, len);//更新局部块剩余数据到校验和对象
byte[] buf = FSOutputSummer.convertToByteStream(partialCrc, checksumSize);
checksumOut.write(buf);//写新的校验和到校验文件中
LOG.debug("Writing out partial crc for data len " + len);
partialCrc = null;//重置partialCrc对象
} else {
checksumOut.write(pktBuf, checksumOff, checksumLen);//写校验数据
}
datanode.myMetrics.incrBytesWritten(len);
///在发送ACK之前刷新整个包
flush();
datanode.data.setVisibleLength(block, offsetInBlock);//更新区块的visible长度
dropOsCacheBehindWriter(offsetInBlock);
}
} catch (IOException iex) {
datanode.checkDiskError(iex);
throw iex;
}
}
如上,通过数据长度计算出校验数据长度。将数据写到临时文件中,而对于局部块的情况,之前将本地局部块保存的局部数据更新到了partialCrc对象中,读取剩余的局部数据到该校验和对象中,重新计算该块的校验和写到校验文件中,如果是局部块,则该包只包含局部块的剩余数据。写完数据到流中后,刷新到本地文件,然后开始接收ACK,更新FSDataset中的区块可视长度。
另外,如果是Client写数据,则只有数据流管道的最后一个节点才需要验证接收到的区块校验和,否则每个接收到数据的数据节点都需要验证校验和。验证校验和通过verifyChunks,如上给定数据和校验数据字节数据,开始偏移量和长度,循环读取数据块进行验证即可,有任何一个数据块验证失败都会导致该区块验证失败,抛出异常。
接收完数据并发送到下游节点后,Client写数据的情况便等待接收ACK了,如果指定了节流器的话,通过节流器判断是否发的太快,应该休眠一会1
2
3
4
5
6
7if (responder != null) {
((PacketResponder)responder.getRunnable()).enqueue(seqno, lastPacketInBlock);
}
if (throttler != null) { // throttle I/O
throttler.throttle(payloadLen);
}
节流器在读请求时已经分析过了,这里分析PacketResponder接收ACK,如上发送完一个包到下游节点后,将该包入队列1
2
3
4
5
6
7synchronized void enqueue(long seqno, boolean lastPacketInBlock) {
if (running) {
LOG.debug("PacketResponder " + numTargets + " adding seqno " + seqno + " to ack queue.");
ackQueue.addLast(new Packet(seqno, lastPacketInBlock));
notifyAll();//通知可能处于休眠等待状态的PacketResponder线程有待接收ACK的包
}
}
创建Packet对象,Packet对象就是包含包序号和是否为最后一个包的简单对象,然后添加到PacketResponder的ackQueue队列尾,通知可能处于等待状态的PacketResponder线程。
5. 接收下游ACK,往上游发送ACK
PacketResponder线程主程序如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100public void run() {
boolean lastPacketInBlock = false;
boolean isInterrupted = false;
final long startTime = ClientTraceLog.isInfoEnabled() ? System.nanoTime() : 0;
while (running && datanode.shouldRun && !lastPacketInBlock) {
try {
//当从下游节点读取ACK失败时,通过包序号为-2通知Client接收失败
long expected = PipelineAck.UNKOWN_SEQNO;//-2
long seqno = PipelineAck.UNKOWN_SEQNO;;//-2
PipelineAck ack = new PipelineAck();
boolean localMirrorError = mirrorError;
try {
Packet pkt = null;
synchronized (this) {
while (running && datanode.shouldRun && ackQueue.size() == 0) {//没有待接收ACK的包,等待
...//日志
wait();
}
if (!running || !datanode.shouldRun) {
break;
}
pkt = ackQueue.removeFirst();//获取队列首元素
expected = pkt.seqno;
notifyAll();
}
if (numTargets > 0 && !localMirrorError) {//如果不是最后一个节点需要接收下游ACK
//从下游节点读一个ACK
ack.readFields(mirrorIn);
...//日志
seqno = ack.getSeqno();
if (seqno != expected) {
throw new IOException("PacketResponder " + numTargets + " for block " +
block + " expected seqno:" + expected + " received:" + seqno);
}
}
lastPacketInBlock = pkt.lastPacketInBlock;
} catch (InterruptedException ine) {//被中断,DataNode关闭
isInterrupted = true;
} catch (IOException ioe) {
if (Thread.interrupted()) {
isInterrupted = true;
} else {
//mirrorError通知上游节点接收下游节点的ACK出错,最终Client会关闭整个数据流管道
mirrorError = true;
LOG.info("PacketResponder " + block + " " + numTargets +
" Exception " + StringUtils.stringifyException(ioe));
}
}
if (Thread.interrupted() || isInterrupted) {
//接受线程关闭了该线程
LOG.info("PacketResponder " + block + " " + numTargets + " : Thread is interrupted.");
break;
}
//如果是最后一个包,则在发送ACK之前,关闭文件并提交到current目录中
if (lastPacketInBlock && !receiver.finalized) {
receiver.close();//关闭BlockReceiver
final long endTime = ClientTraceLog.isInfoEnabled() ? System.nanoTime() : 0;
block.setNumBytes(receiver.offsetInBlock);
datanode.data.finalizeBlock(block);//提交区块到某个存储目录的current中
datanode.myMetrics.incrBlocksWritten();
//添加到DataNode的receivedBlockList中,然后在offerService中向NameNode通知新接收到的区块
datanode.notifyNamenodeReceivedBlock(block, DataNode.EMPTY_DEL_HINT);
...//日志
}
short[] replies = null;
if (mirrorError) { //接收下游ACK出错,下游ACK对应为OP_STATUS_ERROR
replies = new short[2];
replies[0] = DataTransferProtocol.OP_STATUS_SUCCESS;
replies[1] = DataTransferProtocol.OP_STATUS_ERROR;
} else {//正常情况,下游ACK加上本节点状态
short ackLen = numTargets == 0 ? 0 : ack.getNumOfReplies();
replies = new short[1+ackLen];
replies[0] = DataTransferProtocol.OP_STATUS_SUCCESS;
for (int i=0; i<ackLen; i++) {
replies[i+1] = ack.getReply(i);
}
}
PipelineAck replyAck = new PipelineAck(expected, replies);
replyAck.write(replyOut);//发送到上游节点
replyOut.flush();
if (LOG.isDebugEnabled()) {
LOG.debug("PacketResponder " + numTargets + " for block " + block + " responded an ack: " + replyAck);
}
} catch (Throwable e) {
LOG.warn("IOException in BlockReceiver.run(): ", e);
if (running) {
LOG.info("PacketResponder " + block + " " + numTargets +
" Exception " + StringUtils.stringifyException(e));
running = false;
}
if (!Thread.interrupted()) { // error not caused by interruption
receiverThread.interrupt();
}
}
}
LOG.info("PacketResponder " + numTargets + " for " + block +
" terminating");
}
如上,在PacketResponder线程中,如果ackQueue中没有待接收ACK的包则等待,这对应上面往下游节点发送一个包后会将该包添加到ackQueue中,然后通知睡眠线程。
ackQueue队列中有待接收ACK的包,获取队列首元素,为要接收ACK的包,从下游节点输入流中接收一个ACK,如果接收ACK异常且不是被中断,则读取下游ACK失败,这时会往上游节点发送ACK时标记本节点的下游ACK状态为OP_STATUS_ERROR。
如果当前接收ACK的包是最后一个包,则需要将本地临时文件关闭,然后通过DataNode FSDataset的finalizeBlock提交到存储目录中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public void finalizeBlock(Block b) throws IOException { finalizeBlockInternal(b, false); }
private synchronized void finalizeBlockInternal(Block b, boolean reFinalizeOk) throws IOException {
ActiveFile activeFile = ongoingCreates.get(b);
if (activeFile == null) {
if (reFinalizeOk) {
return;
} else {
throw new IOException("Block " + b + " is already finalized.");
}
}
File f = activeFile.file;
if (f == null || !f.exists()) {
throw new IOException("No temporary file " + f + " for block " + b);
}
FSVolume v = volumeMap.get(b).getVolume();//获取所属的存储目录
if (v == null) {
throw new IOException("No volume for temporary file " + f + " for block " + b);
}
File dest = null;
dest = v.addBlock(b, f);//提交,添加到current目录中
volumeMap.put(b, new DatanodeBlockInfo(v, dest));
ongoingCreates.remove(b);
}
如上,获取其所在的存储目录,然后通过FSVolume的addBlock添加到current目录中,该方法分析见DataNode本地存储管理,从current目录下开始,如果没有达到目录下的最大区块文件限制则直接添加到该目录,否则到子目录(sub*)下面添加,会先尝试不创建子目录,所有子目录都没空间添加失败时才会创建子目录。
添加到current目录下后,在volumeMap中创建映射,删除ongoingCreates中的记录。
提交后,通过notifyNamenodeReceivedBlock将区块添加到DataNode的receivedBlockList中,然后在DataNode的offerService中通知NameNode接收到新区块。
往上游节点发送ACK时,如果读取下游节点ACK正常(mirrorError为false),则连接下游节点的ACK,然后在数组首添加自己OP_STATUS_SUCCESS的状态,因此节点接收到ACK时,replies[0]为连接的下游节点ACK,replies[1]为连接的下游节点的下游节点,以此类推。
而如果接收下游节点ACK失败,则初始化下游节点ACK为OP_STATUS_ERROR,发送到上游节点。