Hadoop版本:Hadoop-1.2.1
参考:《Hadoop技术内幕-深入解析Hadoop Common和HDFS架构设计与实现原理》
1. 元数据管理
NameNode中维护的数据节点相关元数据操作,大部分由FSNamesystem对象负责,主要有一下相关数据结构1
2
3
4
5
6
7
8
9public FSDirectory dir;//目录树相关
final BlocksMap blocksMap = new BlocksMap(DEFAULT_INITIAL_MAP_CAPACITY, DEFAULT_MAP_LOAD_FACTOR);//所有区块信息
public CorruptReplicasMap corruptReplicas = new CorruptReplicasMap();//所有损坏区块信息
NavigableMap<String, DatanodeDescriptor> datanodeMap = new TreeMap<String, DatanodeDescriptor>();//所有数据节点
private Map<String, Collection<Block>> recentInvalidateSets = new TreeMap<String, Collection<Block>>();//数据节点待删除区块
Map<String, Collection<Block>> excessReplicateMap = new TreeMap<String, Collection<Block>>();//数据节点超过期望副本的区块
ArrayList<DatanodeDescriptor> heartbeats = new ArrayList<DatanodeDescriptor>();//数据节点
private UnderReplicatedBlocks neededReplications = new UnderReplicatedBlocks();//需要复制的区块
PendingReplicationBlocks pendingReplications;//正在复制区块信息
2. FSDirectory
成员dir为FSDirectory类型,负责目录树相关操作,包括命名空间镜像相关操作,由成员FSImage对象fsImage负责。而FSImage中又包含FSEditLog对象,因此又包括编辑日志相关操作。这些操作实现分析另见命名空间镜像和编辑日志和NameNode和SecondaryNameNode交互
3. BlockMap
成员blocksMap为BlockMap类型,为NameNode维护的所有的区块信息,区块信息对应为BlockInfo,包含了区块所属文件INode对象,所有副本,副本所在数据节点信息(DatanodeDescriptor),根据每个备份可以访问所在数据节点上的所有区块。
BlockMap包含如下成员1
2private final int capacity;
private GSet<Block, BlockInfo> blocks;
capacity为管理的区块数量,blocks为GSet集合,具体实现类为LightWeightGSet,不过提供了类似映射的功能,可以根据数据块Block对象获取对应的BlockInfo对象。
3.1 LightWeightGSet
LightWeightGSet采用链式哈希表的形式存储元素,主要成员如下1
2
3private final LinkedElement[] entries;
private final int hash_mask;
private int size = 0;
entries,为LinkedElement数组,存储实际数据,元素类型为LinkedElement,如下1
2
3
4public static interface LinkedElement {
public void setNext(LinkedElement next);
public LinkedElement getNext();
}BlockInfo实现了该接口
hash_mask,为计算元素在数组中索引的掩码,为数组大小减1,通过元素的哈希码和该掩码获得在数组中索引1
2
3private int getIndex(final K key) {
return key.hashCode() & hash_mask;
}size,数组大小
LightWeighGSet中查找元素的get方法如下1
2
3
4
5
6
7
8
9
10
11
12
13
14@Override
public E get(final K key) {
if (key == null) {
throw new NullPointerException("key == null");
}
final int index = getIndex(key);//获得在数组中索引
for(LinkedElement e = entries[index]; e != null; e = e.getNext()) {
if (e.equals(key)) {
return convert(e);
}
}
return null;
}
如上,LightWeightGSet为链式哈希表的实现形式,查找元素时,首先获取在数组中索引,获得索引中元素后遍历链表,判断两个元素是否相等由LinkedElement的equals方法完成,BlockInfo中实现如下,继承自Block类1
2
3
4
5
6
7
8public boolean equals(Object o) {
if (!(o instanceof Block)) {
return false;
}
final Block that = (Block)o;
return this.blockId == that.blockId
&& GenerationStamp.equalsWithWildcard(this.generationStamp, that.generationStamp);
}
如上,区块ID相等,且generationStamp一致时,两个元素才相等。这里的generationStamp一致允许使用通配符1
2
3public static boolean equalsWithWildcard(long x, long y) {
return x == y || x == WILDCARD_STAMP || y == WILDCARD_STAMP;
}
如上,严格一致,或者任何一个为WILDCARD_STAMP(1)。
3.2 BlockInfo
BlockInfo是Block的子类,包含Block所属INode信息和该区块所有副本所属数据节点信息,并能访问副本所在数据节点的其他区块(数据节点区块链表形式)
BlockInfo成员如下1
2
3private INodeFile inode;//所属INodeFile
private LightWeightGSet.LinkedElement nextLinkedElement;
private Object[] triplets;
如上,inode为区块所属的INodeFile信息,triplets数组,该区块的第i个副本所在数据节点为triplets[3i],为DataNodeDescriptor类型,而triplets[3i+1]为第i个副本所在数据节点该区块的上一个区块,为BlockInfo类型,因为DataNodeDescriptor上所有的区块以双向链表的形式进行管理,triplets[3*i+2]为第i个副本所在数据节点该区块的下一个区块。triplets中保存了DataNodeDescriptor类型,BlockInfo类型,因此为Object对象。
3.3 DataNodeDescriptor
再看看DataNodeDescriptor中的成员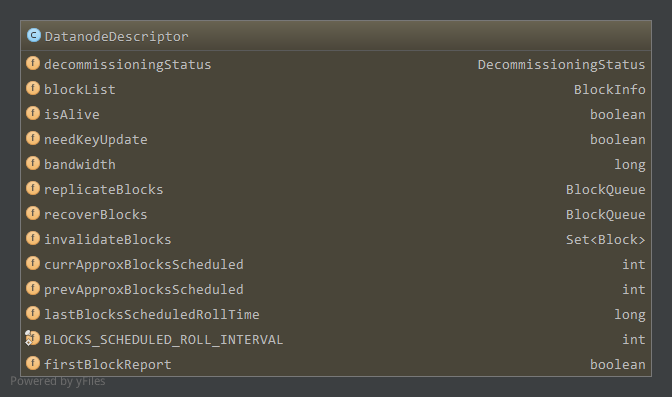
分析主要成员
blockList,为BlockInfo类型,作为DataNode上所有区块信息的链表头,BlockInfo可以通过BlockIterator访问数据节点下一个BlockInfo,blockList即为链表头,BlockIterator如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24static private class BlockIterator implements Iterator<Block> {
private BlockInfo current;//当前区块
private DatanodeDescriptor node;//迭代的数据节点
BlockIterator(BlockInfo head, DatanodeDescriptor dn) {
this.current = head;
this.node = dn;
}
public boolean hasNext() {
return current != null;
}
public BlockInfo next() {
BlockInfo res = current;
//获取DataNodeDescriptor在当前BlockInfo中的索引i,然后通过triplets[3*i+2]获得数据节点上下一个BlockInfo
current = current.getNext(current.findDatanode(node));
return res;
}
public void remove() {
throw new UnsupportedOperationException("Sorry. can't remove.");
}
}如上,next方法中,首先遍历当前区块BlockInfo,找到DataNodeDescriptor在triplets中的索引,通过triplets[3*i+2]获得下一个BlockInfo。
bandwidth,数据节点相关分析中宽带均衡器的带宽,可以更新replicateBlocks,数据节点上需要复制的区块,为BlockQueue类型,成员如下1
private final Queue<BlockTargetPair> blockq = new LinkedList<BlockTargetPair>();
如上,为双向链表,元素类型为
BlockTargetPair,包含区块和对该区块执行相应操作目标数据节点信息,成员如下1
2public final Block block;//区块
public final DatanodeDescriptor[] targets;//区块执行相应操作的目的数据节点因此,replicatedBlocks中,每一个需要复制的区块,有一个对应的BlockTargetPair对象,包含了需要复制到的数据节点信息
recoverBlocks,数据节点上需要恢复的区块,本数据节点为NameNode选取的恢复时主数据节点,同样的为BlockQueue类型,因此参与恢复的数据节点在Block对应的BlockTargetPair中,其中本数据节点字节也在其中。invalidateBlocks,数据节点上应该删除的区块,为Set类型,具体实现为TreeSet有序集。
如上,通过blockList可访问数据节点上所有区块。
NameNode处理相关操作的过程中,发现某些区块副本数没有达到指定值,则会选择源数据节点复制到目标数据节点,以内次会在源数据节点的replicateBlocks中添加该区块信息,包括目标数据节点。在该数据节点的下一次心跳报告时根据replicateBlocks发送DNA_TRANSFER命令,然后数据节点会执行复制过程。
同样的,NameNode在租约恢复时会先将区块恢复到一致状态,因此会选择一个主数据节点,以及其他有副本数参与恢复的数据节点进行恢复。添加需要恢复的区块信息到主数据节点的recoverBlocks中,包含其他参与恢复的数据节点信息。在主数据节点的下一次心跳报告时根据recoverBlocks发送DNA_RECOVERBLOCK命令,然后数据节点会执行区块恢复过程。
对于数据节点上需要删除的区块,NameNode会更新在数据节点的invalidateBlocks中,然后在数据节点的下一次心跳报告时根据invalidateBlocks发送DNA_INVALIDATE命令,数据节点执行相应的删除操作。
还有其他的如宽带更新也是这样,先更新在bandwidth中,然后心跳到来时根据bandwidth进行相应的DNA_BALANCERBANDWIDTHUPDATE命令下达,还有安全相关的访问令牌更新通过DNA_ACCESSKEYUPDATE命令。
4. CorruptReplicasMap
成员corruptReplicas为CorruptReplicasMap类型,包含的成员如下1
private Map<Block, Collection<DatanodeDescriptor>> corruptReplicasMap = new TreeMap<Block, Collection<DatanodeDescriptor>>();
键为Block,值为DataNodeDescriptor集合有序映射。为NameNode维护的所有损坏区块和对应所在的数据节点关系。
4.1 添加记录
- 数据节点区块报告时和名字节点对应元数据不一致,如大小不一样且对应文件并不处于写状态,添加区块和对应的数据节点
- 数据节点区块读写过程发现区块损坏,或者区块扫描器扫描发现区块损坏(验证校验和),通过reportBadBlocks进行损坏区块报告,添加区块和对应数据节点(markBlockAsCorrupt中)
4.2 移除记录
- 区块在数据节点上被删除时(可能因为多种原因被删除),移除被删除区块和对应的数据节点记录(removeBlock,removeBlocks中)
- 区块报告发现损坏区块的正常副本数达到了要求,会删除所有的损坏区块副本,同时在corruptReplicas中移除该区块以及所有的数据节点记录(addStoredBlock->invalidateCorruptReplicas中)
- 区块报告时,如果区块在数据节点上已经被删除了(数据节点上没记录,NameNode元数据有记录,需要通过removeStoredBlock移除NameNode中元数据),在removeStoredBlock中,如果corruptReplicationsMap中有该区块和数据节点记录,则删除该记录(removeStoredBlock中)
5. datanodeMap
成员datanodeMap,管理了所有的数据节点,为TreeMap类型。键为数据节点的StorageID,值为NameNode端的数据节点对象DatnodeDescriptor。
其中的元素可能有以下情况:(参考注释)
- 添加,添加一个拥有新存储ID的新的数据节点
- 更新,更新数据节点,还是使用原来的存储ID
- 移除,当且仅当数据节点重启,使用新的存储ID
6. recentInvalidateSets
成员recentInvalidateSets为TreeMap类型,键为数据节点的存储ID StorageID,值为Block集合ArrayList。
为NameNod维护的每个数据节点上应该删除的区块。
6.1 添加记录
- 处理超过指定副本数的区块时(processOverReplicatedBlock,如重新设置了副本数,接收到一个区块然后副本数超过阈值),会选择某些数据节点上的副本删除,添加到recentInvalidateSets中(chooseExcessReplicates中)
- 区块损坏处理时,发现对应的INode文件在NameNode中不存在,该损坏区块需要删除(markBlockAsCorrupt中)
- 区块损坏处理时,发现有效副本数已经达到了要求,损坏区块需要删除(markBlockAsCorrupt中)
- 区块报告中发现损坏区块的正常副本数达到了要求,会删除corruptReplicas中该区块所有的损坏区块副本(addStoredBlock->invalidateCorruptReplicas中)
- 区块报告时(周期性报告或BlocksBeingWrittenReport),报告的区块与NameNode中元数据不匹配(如BlockInfo不存在,INode对象不存在,状态不匹配等),需要删除该区块(processBlocksBeingWrittenReport,addStoredBlock的rejectAddStoredBlock中)
- 区块报告时,数据节点中已经删除的,需要删除对应的区块元数据(processReport中)
- 删除文件或目录时,删除对应的区块(removeBlocks)
6.2 移除记录
- 在ReplicationMonitor线程中添加到相应的DatanodeDescriptor的invalidateBlocks成员中,添加完后在recentInvalidateSets中移除。如果数据节点对应所有应该删除的区块都添加到了DatanodeDescriptor的invalidateBlocks中了,移除该条映射(invalidateWorkForOneNode)
- 移除数据节点时,删除在recentInvalidateSets中的所有区块记录(removeDatanode)
- 处理recentInvalidateSets中的区块记录,即添加到对应DatanodeDescriptor中的invalidateBlocks中,发现DatanodeDescriptor在datanodeMap中不存在了,移除该数据节点在recentInvalidateSets中所有记录(invalidateWorkForOneNode)
7. excessReplicateMap
成员excessReplicateMap也是TreeMap,键为数据节点的StorageID,值为该数据节点上超出副本数要求的区块集合。
7.1 添加记录
- 当更改(减少)了副本数,或者接收到一个区块导致有效副本数超出期望值,需要通过processOverReplicatedBlock处理超出的副本数,对所有的副本数通过
chooseExcessReplicates选择一些数据节点上的副本添加到excessReplicateMap中(同时会添加到recentInvalidateSets中删除)
7.2 移除记录
- 区块报告时,发现数据节点上区块已经被删除,如果该区块在excessReplicateMap中,需要从数据节点对应的映射重移除区块记录,即之前添加到excessReplicateMap,然后进行删除操作已经完成。如果该数据节点上所有超出副本数的区块已经被删除了,则移除该数据节点的映射(processReport->removeStoredBlock中)
- 如果数据节点上某一区块损坏或者超过副本限制,需要移除数据节点上该区块时(invalidateBlock->removeStoredBlock中),注意这里和上面不同之处,上面为数据节点的区块报告,而这里是NameNode因为其他原因发现需要删除数据节点上某一区块元数据。
- 移除数据节点,因此要移除所有区块时(removeDatanode->removeStoreBlock中)
8. heartbeats
成员heartbeats是datanodeMap的子集,注册时添加,数据节点出错应该移除关闭时移除
9. neededReplications
成员neededReplications维护了副本数没有达到期望值,需要复制的所有区块,是UnderReplicatedBlocks类,如下
9.1 UnderReplicatedBlocks
1 | class UnderReplicatedBlocks implements Iterable<Block> { |
成员priorityQueues包含三个优先级队列,如果区块没有达到副本数要求,根据其目前的备份数等信息可得其对应的优先级
9.1.1 getPriority
1 | private int getPriority(Block block, int curReplicas, int decommissionedReplicas, int expectedReplicas) { |
如上,如果副本数小于0或者已经达到了期望值,不需要复制,优先级为3。如果副本数为0,不过在正在关闭的数据节点上还有副本数,则分配最高优先级,即尽快从正在关闭的数据节点上复制到其他节点。而如果副本数为0同时在正在关闭的数据节点上没有副本数,则优先级最低,保持在队列中。
如果只有一个副本,优先级最高,尽快从剩下的一个副本复制到其他节点。
如果副本数小于1/3,优先级次之为1,否则为2。
neededReplications由ReplicationMonitor线程处理。按照优先级选出待复制Block,然后选择源数据节点和目标数据节点,将区块和目标数据节点信息添加到源数据节点的replicateBlocks中,并在pendingReplications中对应区块正在执行的复制请求中加1。在该源数据节点下次心跳到来时发送DNA_TRANSFER命令,复制到目标数据节点。
9.2 添加记录
- 关闭正在写的文件(可能为正常关闭completeFileInternal,可能是NameNode发起的租约恢复后关闭internalReleaseLeaseOne,也可能为DataNode区块恢复后通知NameNode关闭)时,会通过checkReplicationFactor对文件所有区块进行副本数检查,如果副本数没有达到期望值,添加到neededReplications中(checkReplicationFactor中)
- ReplicationMonitor线程将neededReplications中区块信息添加到相应源数据节点的replicateBlocks中后,会相应的在pendingReplications增加区块正在复制操作的次数,如果pendingReplications中记录长时间没有移除(由PendingReplicationMonitor线程检查),表示复制操作长时间没有完成,重新添加到neededReplications中执行复制(ReplicationMonitor线程processPendingReplications中)
- FSNamesystem成员dnthread DecommissionManager.Monitor会周期性检查目前处于
DECOMMISSION_INPROGRESS状态的数据节点,看其所有的区块副本数是否满足期望值,如果所有区块达到了期望值则更新状态为DECOMMISSIONED,即该数据节点不会参与复制操作,可以关闭。在检查过程中,如果某个区块没达到期望值,且在neededReplications中不存在,且当前没有正在执行的复制操作,则添加到neededReplications中(isReplicationInProgress中)
9.3 更新优先级
当区块当前有效副本数或者期望副本数改变时,优先级改变,需要从一个优先级队列移到另一个优先级队列,更新通过update方法完成,如果先后优先级不一样,从原来优先级移除(之前不存在队列中当然不会移除),然后新的优先级在[0,2]范围内添加到对应队列,有如下情况
- 期望副本数改变(setReplicationInternal中)
- 区块损坏(可能数据节点发现报告或者NameNode接收区块报告时发现和元数据不一致)时,或者种种原因删除一个区块副本元数据时,有效副本数降低(markBlockAsCorrupt中)
- 区块报告中,接收了一个新的区块,该区块有效副本数增加(addStoredBlock)
9.4 移除记录
- 在ReplicationMonitor线程中,对每一个选择到的待复制Block,在选择完源数据节点或目的数据节点后,如果发现其对应的INode对象在blocksMap中不存在了或者说对应的INode是INodeFileUnderConstruction,即还未关闭不能执行复制操作,这时需要从neededReplications移除。注意的是,选择完源数据节点会进行一次判断,选择完目标数据节点后也会进行一次判断(computeReplicationWorkForBlock中)
- 在ReplicationMonitor线程中,选择待复制的Block后,在选择完源数据节点或目标数据节点后,如果发现当前有效副本数加上正在复制的副本数达到了期望值,则不需要复制了,从neededReplications中移除,同样的会进行两次判断。(computeReplicationWorkForBlock中)
- 在ReplicationMonitor线程中,选择待复制Block,正常选择好源数据节点或目标数据节点,将区块和要复制到的目标数据节点信息添加到源数据节点的replicateBlocks中后,会在下次心跳发送复制命令。因此复制相关信息添加到源数据节点后,基本相应的增加了正在复制的操作为目标数据节点个数,如果原来有效副本数(实际副本数加上pendingReplications中正在复制记录)加上新增的要执行复制操作的个数如果达到了期望值,则从neededReplications中移除(computeReplicationWorkForBlock中)
- 接收到新的区块(区块报告或者数据节点的BlockReceived通知)时,会相应的增加该区块的副本数,如果达到了期望值则从neededReplications中移除(addStoredBlock中)
10. pendingReplications
如上1.8所述,pendingReplications维护了正在执行复制的区块信息,为PendingReplicationBlocks类,主要成员如下
10.1 PendingReplicationBlocks
1 | private Map<Block, PendingBlockInfo> pendingReplications; |
pendingReplications为HashMap,键为Block,值为Block正在复制的相关信息,为PendingBlockInfo类,如下1
2private long timeStamp;
private int numReplicasInProgress;
timeStamp为创建时间,numReplicasInProgress为该区块正在执行复制的份数,如前所述当ReplicationMonitor线程将neededReplications中Block选择源数据节点目标数据节点后,复制相关信息记录到源数据节点的replicateBlocks中,然后在pendingReplications中将numReplicasInProgress增加目标数据节点个数,即当期正在复制的份数增加。
成员timedOutItems为复制超时的区块,即指定时间内还没从pendingReplications中移除,指定时间内复制没有完成,超时区块会重新添加到neededReplications中重新执行复制操作。超时的判断由PendingReplicationMonitor线程完成,线程为成员timerThread。线程默认5min检查一次,且复制操作超时时间为5min。
构造如下1
2
3
4
5
6
7
8
9
10
11
12
13PendingReplicationBlocks(long timeoutPeriod) {
if ( timeoutPeriod > 0 ) {
this.timeout = timeoutPeriod;
}
init();
}
void init() {
pendingReplications = new HashMap<Block, PendingBlockInfo>();
timedOutItems = new ArrayList<Block>();
this.timerThread = new Daemon(new PendingReplicationMonitor());
timerThread.start();
}
10.2 PendingReplicationMonitor线程
PendingReplicationMonitor线程如下1
2
3
4
5
6
7
8
9
10
11public void run() {
while (fsRunning) {
long period = Math.min(defaultRecheckInterval, timeout);
try {
pendingReplicationCheck();
Thread.sleep(period);//缺省5min检查一次
} catch (InterruptedException ie) {
FSNamesystem.LOG.debug("PendingReplicationMonitor thread received exception. " + ie);
}
}
}
由pendingReplicationCheck执行检查1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20void pendingReplicationCheck() {
synchronized (pendingReplications) {
Iterator iter = pendingReplications.entrySet().iterator();
long now = FSNamesystem.now();
FSNamesystem.LOG.debug("PendingReplicationMonitor checking Q");
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
PendingBlockInfo pendingBlock = (PendingBlockInfo) entry.getValue();
//当前时间超过了该Block记录的超时阈值(从创建开始的5min),超时,添加到timedOutItems中
if (now > pendingBlock.getTimeStamp() + timeout) {
Block block = (Block) entry.getKey();
synchronized (timedOutItems) {
timedOutItems.add(block);//添加到timedOutItems中
}
FSNamesystem.LOG.warn( "PendingReplicationMonitor timed out block " + block);
iter.remove();//移除超时Block记录
}
}
}
}
如上,默认情况下,创建开始后,如果5min内该Block的复制操作还没完成(完成后会从pendingReplications中移除),则会添加到timedOutItems中,而timedOutItems中的Block会在ReplicationMonitor线程中由processPendingReplications重新添加到neededReplications中。