Hadoop版本:Hadoop-1.2.1
参考:《Hadoop技术内幕-深入解析Hadoop Common和HDFS架构设计与实现原理》
编解码器
Hadoop中每一种压缩/解压算法有一个对应的编解码器,编解码器接口为CompressionCodec1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public interface CompressionCodec {
//通过给定输出流out创建压缩输出流,即往输出流写数据时,写入的数据是压缩后的数据
CompressionOutputStream createOutputStream(OutputStream out) throws IOException;
//指定压缩器为out创建压缩输出流
CompressionOutputStream createOutputStream(OutputStream out, Compressor compressor) throws IOException;
//返回当前编解码器对应的压缩器
Class<? extends Compressor> getCompressorType();
//创建压缩器
Compressor createCompressor();
//从给定的输入流in中创建解压输入流,即从中读取数据时,先解压,得到解压后的数据
CompressionInputStream createInputStream(InputStream in) throws IOException;
//指定解压器为输入流in创建解压输入流
CompressionInputStream createInputStream(InputStream in, Decompressor decompressor) throws IOException;
//返回当前编解码器对应的解压器
Class<? extends Decompressor> getDecompressorType();
//创建解压器
Decompressor createDecompressor();
//获取当前压缩算法缺省的文件扩展名
String getDefaultExtension();
}
该接口的相关实现如下: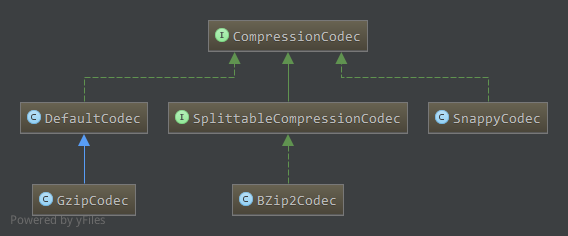
每一种压缩格式对应一种编解码器,SplittableCompressionCodec接口下的实现类压缩后文件可分割(MapReduce任务中)
相关信息如下(参考<技术内幕>)
|压缩格式|UNIX工具|算法|文件扩展名|支持多文件压缩|可分割|编解码器|
|:—:|:—:|:—:|:—:|:—:|:—:|:—:|
|DEFLATE|无|DEFLATE|.deflate|否|否|DefaultCodec|
|gzip|gzip|DEFLATE|.gz|否|否|GzipCodec|
|zip|zip|DEFLATE|.zip|是|是| |
|bzip|bzip2|bzip2|.bz2|否|是|BZip2Codec|
LZO|lzop|LZO|.lzo|否|否| |
另外,SnappyCodec对应Snappy压缩格式
编解码器工厂CompressionCodecFactory
CompressionCodecFactory应用了工厂方法,可以通过它创建不同的CompressionCodec对象。
成员属性
1 | private SortedMap<String, CompressionCodec> codecs = null;//"文件名后缀反转值-编解码器"有序对 |
构造
1 | public CompressionCodecFactory(Configuration conf) { |
如上,构建时根据配置conf中的”io.compression.codec”配置相应的CompressionCodec类,以”,”分割。
若没有配置该项,则默认会添加GzipCodec和DefaultCodec两项。
添加时,简单名若以Codec结束,还要增加去掉Codec的简单名至codecsByName中。如GzipCodec在codecsByName中对应两项,键值为:GzipCodec和Gzip。
通过工厂创建实例
通过文件名创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public CompressionCodec getCodec(Path file) {
CompressionCodec result = null;
if (codecs != null) {
String filename = file.getName();
String reversedFilename = new StringBuffer(filename).reverse().toString();//文件名后缀反转
SortedMap<String, CompressionCodec> subMap = codecs.headMap(reversedFilename);//返回开始项到匹配项的视图
if (!subMap.isEmpty()) {
String potentialSuffix = subMap.lastKey();//取最后一项
if (reversedFilename.startsWith(potentialSuffix)) {
result = codecs.get(potentialSuffix);
}
}
}
return result;
}从codecs中通过headMap获取文件名后缀反转值最接近的有序映射部分视图。
若codecs中按顺序对应的键为[2zb. etalfed. yppans. zg],当输入文件名后缀为”.bz2”时,上述subMap只包含键为2zb.的项,而当文件后缀为”.snappy”时,subMap包含从2zb.到yppans.键对应的项,取最后一项即为结果。通过类名创建
1
2
3
4
5
6public CompressionCodec getCodecByClassName(String classname) {
if (codecsByClassName == null) {
return null;
}
return codecsByClassName.get(classname);
}使用codecsByClassName查找即可
通过名字创建
1
2
3
4
5
6
7
8
9
10public CompressionCodec getCodecByName(String codecName) {
if (codecsByClassName == null) {
return null;
}
CompressionCodec codec = getCodecByClassName(codecName);
if (codec == null) {
codec = codecsByName.get(codecName.toLowerCase());
}
return codec;
}给定名字可能为一个类名,因此先从codecsByClassName中查找,找不到再在codecsByName中查找。
压缩解压器
压缩器接口
1 | public interface Compressor { |
finish函数返回true表示不再有待压缩的输入数据了,而finished函数返回true表示压缩器缓冲中没有未压缩的数据,已经全部压缩并输出了。
给定待压缩数据,若判断needsInput为true时,每次往压缩器中送固定长度的数据,而当needsInput为false时,通过compress函数压缩并读取压缩数据,释放压缩器缓冲区。
当所有待压缩数据都写入了压缩器时,调用finish函数通知压缩器不再有输入。
然后通过finished函数判断压缩器缓冲中的数据是否全部压缩并输出,没有的话通过compress压缩并输出。最终调用end函数完成整个压缩过程。
简单代码举例(参考<技术内幕>)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25Compressor compressor=new ...//创建压缩器
byte[] inbuf=... //待压缩数据字节数组
int length=...//inbuf数据长度
byte[] outbuf=...//outbuf为压缩后数据存储数组
int outlen=...//outbuf数据长度
int step=...//每次从inbuf中往压缩器中送step个字节的数据
int pos=...//当前处理的inbuf中位置,初始化为0
int compressedlen=0;
while(pos<length){//输入缓冲还有数据
int len=(length-pos>=step)?step:(length-pos);//每次往压缩器写的数据长度
compressor.setInput(inbuf,pos,len);//添加待压缩的数据
while(!compressor.needsInput()){
//如果压缩器暂时不需要添加数据(如待压缩缓冲区满),压缩数据并输出
compressedlen=compressor.compress(outbuf,0,outlen);
}
pos+=len;
}
compressor.finish();//所有输入数据写到压缩器中,通知压缩器
while(!compressor.finished()){//压缩器中还有未压缩的数据,压缩并输出
compressor.compress(outbuf,0,outlen);
}
//此时finished()为true,所有数据已经压缩并输出,end()终止。
compressor.end();
解压器接口
1 | public interface Decompressor { |
解压过程与压缩过程类似,都是循环往解压器中送待解压数据,如果解压器暂时不需要添加数据,则通过decompress函数解压并输出数据。所有数据添加完后,调用finish()函数表示没有剩余的待解压数据输入。然后解压并输出解压器中的剩余数据(如果有),最终end函数终止。
目前Hadoop相关实现类如下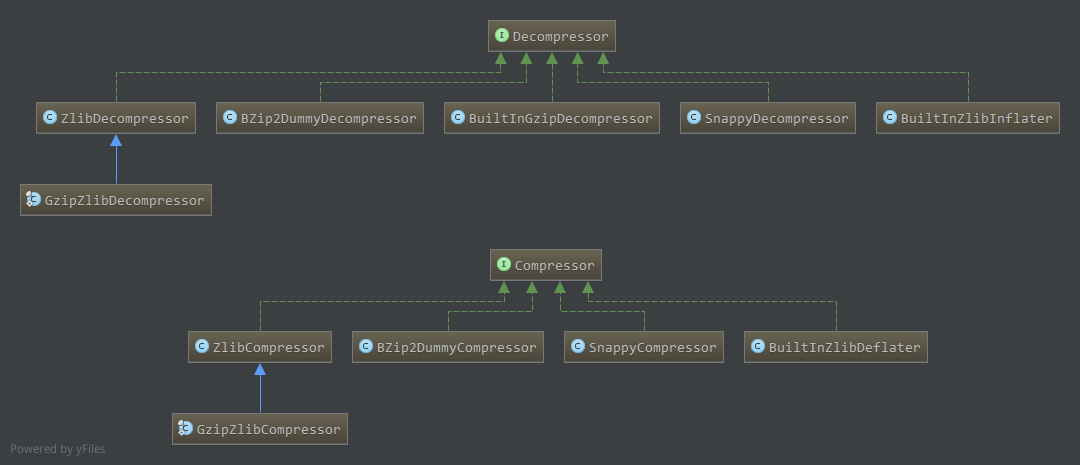
SnappyCompressor(参考<技术内幕>)
成员属性
1 | private static final int DEFAULT_DIRECT_BUFFER_SIZE = 64 * 1024;//缺省直接内存Buffer大小 |
如上,SnappyCompressor中使用两个直接内存缓冲区分别保存添加的待压缩数据和已压缩数据,关于Buffer另见NIO 缓冲区。
同时,遇到添加数据至待压缩数据缓冲区,而此时剩余空间不够时,需要暂时将待添加的数据暂存在额外的缓冲区userBuf中。
构造
1 | public SnappyCompressor() { |
通过ByteBuffer分配直接内存缓冲区(分配另见NIO 缓冲区),并将已压缩缓冲区的position置为limit值,即remaining值为0,没有已压缩的数据。
主要方法
添加待压缩数据setInput
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23@Override
public synchronized void setInput(byte[] b, int off, int len) {
if (b == null) {
throw new NullPointerException();
}
if (off < 0 || len < 0 || off > b.length - len) {
throw new ArrayIndexOutOfBoundsException();
}//合理性检查
finished = false;
if (len > uncompressedDirectBuf.remaining()) {
//待压缩缓冲区剩余空间不足以添加这些数据,暂时保存在userBuf中,之后便需要调用compress压缩并释放待压缩缓冲区了,然后读取userBuf
//中暂存数据到待压缩数据缓冲区中
// save data; now !needsInput
this.userBuf = b;
this.userBufOff = off;
this.userBufLen = len;
} else {//待压缩缓冲区剩余空间足够添加这些数据,添加
((ByteBuffer) uncompressedDirectBuf).put(b, off, len);
uncompressedDirectBufLen = uncompressedDirectBuf.position();
}
bytesRead += len;
}如上,如果能够添加进待压缩数据缓冲区中,则直接添加,否则暂存在userBuf中,接下来应该compress压缩并释放待压缩数据缓冲区,释放后下一次需要读取userBuf中的暂存数据。
是否能够继续添加待压缩数据needsInput
1
2
3
4
5@Override
public synchronized boolean needsInput() {
return !(compressedDirectBuf.remaining() > 0
|| uncompressedDirectBuf.remaining() == 0 || userBufLen > 0);
}看什么情况下不能继续添加待压缩数据(即需要压缩数据并释放缓冲区)。
第一,已压缩缓冲区中还有数据未读取完,不能继续添加;
第二,待压缩缓冲区中没有剩余空间,不能继续添加;
第三,userBuf中有暂存数据,不能继续添加(这时可能待压缩数据缓冲区中还有剩余空间,只是不能保存userBuf暂存的全部数据);finished
1
2
3
4
5@Override
public synchronized boolean finished() {
// Check if all uncompressed data has been consumed
return (finish && finished && compressedDirectBuf.remaining() == 0);
}finish标志置位表示没有待压缩数据输入了,finished标志置位表示待压缩数据缓冲区中没有剩余数据了。
因此当待压缩数据全部添加到压缩器中,待压缩缓冲区没有剩余数据(此时全部输入数据压缩完成,大部分数据已经输出,可能有一部分数据在已压缩数据缓冲区中),且已压缩数据缓冲区中没有未读取的数据时,所有输入数据已经压缩并输出了。压缩待压缩数据缓冲区中数据compress
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58@Override
public synchronized int compress(byte[] b, int off, int len)
throws IOException {
//合理性检查
...
int n = compressedDirectBuf.remaining();
if (n > 0) {//如果已压缩数据缓冲区中还有数据,则直接读取数据输出
n = Math.min(n, len);
((ByteBuffer) compressedDirectBuf).get(b, off, n);
bytesWritten += n;
return n;
}
//已压缩数据缓冲区没有数据,clear(准备写入put)并将limit置0(remaining=0)
compressedDirectBuf.clear();
compressedDirectBuf.limit(0);
//见上needsInput条件,上面已经处理了有已压缩数据没读取的情况,这里position为0,则userBuf中有数据,读取数据至待压缩缓冲区中。
if (0 == uncompressedDirectBuf.position()) {
// No compressed data, so we should have !needsInput or !finished
setInputFromSavedData();//从userBuf中读取数据至uncompressedDirectBuf中
if (0 == uncompressedDirectBuf.position()) {//userBuf中没有数据,所有数据处理完
// Called without data; write nothing
finished = true;
return 0;
}
}
// Compress data
n = compressBytesDirect();//压缩数据,将uncompressedDirectBuf中待压缩数据压缩,压缩后数据保存在compressedDirectBuf中
compressedDirectBuf.limit(n);//compressedDirectBuf有数据了,设置limit值,等待读取
uncompressedDirectBuf.clear(); // snappy consumes all buffer input,准备继续读取待压缩的输入数据
// Set 'finished' if snapy has consumed all user-data
if (0 == userBufLen) {
finished = true;
}
// Get atmost 'len' bytes
n = Math.min(n, len);
bytesWritten += n;
((ByteBuffer) compressedDirectBuf).get(b, off, n);//压缩完后读取数据到输出字节数组b中
return n;
}
synchronized void setInputFromSavedData() {
if (0 >= userBufLen) {//没有数据,直接返回,对应上面待压缩缓冲区position为0,所有数据处理完
return;
}
finished = false;
uncompressedDirectBufLen = Math.min(userBufLen, directBufferSize);
((ByteBuffer) uncompressedDirectBuf).put(userBuf, userBufOff, uncompressedDirectBufLen);//读取数据至待压缩缓冲区
// Note how much data is being fed to snappy
userBufOff += uncompressedDirectBufLen;
userBufLen -= uncompressedDirectBufLen;
}如上,如果已压缩缓冲区中有数据尚未读取,则直接读取数据。
否则压缩待压缩缓冲区的数据至已压缩缓冲区,压缩后读取数据输出。
而这里如果发现待压缩数据缓冲区没有可用数据,表明需要从userBuf这一暂存区中读取数据,然后压缩输出。最终压缩是通过
compressBytesDirect方法来完成1
private native int compressBytesDirect();
该方法为本地实现,另外还有一个本地方法
1
private native static void initIDs();
本地库(参见<技术内幕>)
如上,SnappyCompressor最终压缩为本地方法,要实现本地方法,一般需要三个步骤:
- 为方法生成一个在Java调用和实际C函数间转换的C存根;
- 建立一个共享库并导出该存根;
- 使用System.loadLibrary()通知Java运行环境加载共享库;
JDK为C存根的生成提供了使用程序javah,可以在build/classes目录下执行:1
javah oar.apache.hadoop.io.compress.snappy.SnappyCompressor
系统会生成一个头文件org_apache_hadoop_io_compress_snappy_SnappyCompressor.h,包含SnappyCompressor中两个本地方法的声明:1
2JNIEXPORT void JNICALL Java_org_apache_hadoop_io_compress_snappy_SnappyCompressor_initIDs(JNIEnv *, jclass);
JNIEXPORT jint JNICALL Java_org_apache_hadoop_io_compress_snappy_SnappyCompressor_compressBytesDirect(JNIEnv *, jobject);
声明中JNIEXPORT和JNICALL表明这两个方法会被JNI调用。
参数JNIEnv指针用于和JVM通信,JNIEnv提供了大量的函数,可以执行类和对象的相关方法,也可以访问对象的成员变量或类的静态变量。
参数jclass提供了引用静态方法对应类的机制。
jobject可以理解为this引用。
有了上述头文件,可以对两个方法做相应实现,实现在目录$HADOOP_HOME/src/native/src/org/apache/hadoop/io/compress下,压缩部分对应的C源代码时SnappyCompressor.c文件,如下:
看相应实现1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67static snappy_status (*dlsym_snappy_compress)(const char*, size_t, char*, size_t*);//压缩方法对应函数指针
JNIEXPORT void JNICALL Java_org_apache_hadoop_io_compress_snappy_SnappyCompressor_initIDs
(JNIEnv *env, jclass clazz){
// Load libsnappy.so
//加载snappy动态库
void *libsnappy = dlopen(HADOOP_SNAPPY_LIBRARY, RTLD_LAZY | RTLD_GLOBAL);
if (!libsnappy) {
char* msg = (char*)malloc(1000);
snprintf(msg, 1000, "%s (%s)!", "Cannot load " HADOOP_SNAPPY_LIBRARY, dlerror());
THROW(env, "java/lang/UnsatisfiedLinkError", msg);
return;
}
// Locate the requisite symbols from libsnappy.so
dlerror(); // Clear any existing error
//加载压缩函数dlsym_snappy_compress为动态库中snappy_compress函数
LOAD_DYNAMIC_SYMBOL(dlsym_snappy_compress, env, libsnappy, "snappy_compress");
//初始化加载SnappyCompressor中成员类型
SnappyCompressor_clazz = (*env)->GetStaticFieldID(env, clazz, "clazz", "Ljava/lang/Class;");
SnappyCompressor_uncompressedDirectBuf = (*env)->GetFieldID(env, clazz,"uncompressedDirectBuf","Ljava/nio/Buffer;");
SnappyCompressor_uncompressedDirectBufLen = (*env)->GetFieldID(env, clazz, "uncompressedDirectBufLen", "I");
SnappyCompressor_compressedDirectBuf = (*env)->GetFieldID(env, clazz, "compressedDirectBuf", "Ljava/nio/Buffer;");
SnappyCompressor_directBufferSize = (*env)->GetFieldID(env, clazz, "directBufferSize", "I");
}
JNIEXPORT jint JNICALL Java_org_apache_hadoop_io_compress_snappy_SnappyCompressor_compressBytesDirect
(JNIEnv *env, jobject thisj){//compressBytesDirect方法C实现
// Get members of SnappyCompressor
//通过JNI的JNIEnv指针获取SnappyCompressor成员属性
jobject clazz = (*env)->GetStaticObjectField(env, thisj, SnappyCompressor_clazz);
jobject uncompressed_direct_buf = (*env)->GetObjectField(env, thisj, SnappyCompressor_uncompressedDirectBuf);
jint uncompressed_direct_buf_len = (*env)->GetIntField(env, thisj, SnappyCompressor_uncompressedDirectBufLen);
jobject compressed_direct_buf = (*env)->GetObjectField(env, thisj, SnappyCompressor_compressedDirectBuf);
jint compressed_direct_buf_len = (*env)->GetIntField(env, thisj, SnappyCompressor_directBufferSize);
// Get the input direct buffer
//uncompressedDirectBuf成员,即待压缩缓冲区对应在内存中的地址
LOCK_CLASS(env, clazz, "SnappyCompressor");
const char* uncompressed_bytes = (const char*)(*env)->GetDirectBufferAddress(env, uncompressed_direct_buf);
UNLOCK_CLASS(env, clazz, "SnappyCompressor");
if (uncompressed_bytes == 0) {
return (jint)0;
}
// Get the output direct buffer
//compressedDirectBuf成员,即已压缩缓冲区在内存中地址
LOCK_CLASS(env, clazz, "SnappyCompressor");
char* compressed_bytes = (char *)(*env)->GetDirectBufferAddress(env, compressed_direct_buf);
UNLOCK_CLASS(env, clazz, "SnappyCompressor");
if (compressed_bytes == 0) {
return (jint)0;
}
//压缩,通过函数dlsym_snappy_compress完成
snappy_status ret = dlsym_snappy_compress(uncompressed_bytes, uncompressed_direct_buf_len, compressed_bytes, &compressed_direct_buf_len);
if (ret != SNAPPY_OK){
HROW(env, "Ljava/lang/InternalError", "Could not compress data. Buffer length is too small.");
}
//压缩完成,更新SnappyCompressor中的成员
(*env)->SetIntField(env, thisj, SnappyCompressor_uncompressedDirectBufLen, 0);
return (jint)compressed_direct_buf_len;
}
如上,可通过JNIEnv的GetStaticFieldID,GetFieldID和指定的clazz分别获取Java中静态成员和非静态成员的ID,然后通过GetStaticObjectField,GetObjectField,GetIntField以及指定的this对象thisj分别获取静态对象成员,非静态对象成员和其他属性(Int)的成员属性,然后通过GetDirectBufferAddress获取直接内存对应的内存地址。
编码通过函数指针dlsym_snappy_compress完成,在initIDs中初始化。initIDs中加载libsnappy.so动态库,然后将dlsym_snappy_compress初始化为动态库中的snappy_compress方法。
要使用snappy本地库,需要将这些本地头文件和实现c文件编译连接成动态库(打包成libhadoop.so),在运行时要将Snappy的动态库加载进来。
因此,在运行时,需要将包含Snappy动态库的路径放在系统属性java.library.path中,这样Java虚拟机才能找到对应的动态库。最后,Java应用需要显式通知Java运行环境加载相关的动态库(Snappy动态库),对应SnappyCompressor中静态代码段1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18static {
if (LoadSnappy.isLoaded()) {
// Initialize the native library
try {
initIDs();
} catch (Throwable t) {
// Ignore failure to load/initialize snappy
LOG.warn(t.toString());
}
} else {
LOG.error("Cannot load " + SnappyCompressor.class.getName() +
" without snappy library!");
}
}
public static boolean isLoaded() {
return LOADED;
}
在initIDs实现中会加载HADOOP_SNAPPY_LIBRARY,而在LoadSnappy的静态代码段中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16static {
try {
System.loadLibrary("snappy");//加载"java.library.path"路径下的snappy动态库
LOG.warn("Snappy native library is available");
AVAILABLE = true;
} catch (UnsatisfiedLinkError ex) {
//NOP
}
boolean hadoopNativeAvailable = NativeCodeLoader.isNativeCodeLoaded();
LOADED = AVAILABLE && hadoopNativeAvailable;
if (LOADED) {
LOG.info("Snappy native library loaded");
} else {
LOG.warn("Snappy native library not loaded");
}
}
压缩流和解压流
在CompressionCodec中还提供了创建相应压缩流和解压流的方法,可以同时指定所用的压缩器/解压器。
相应类图如下: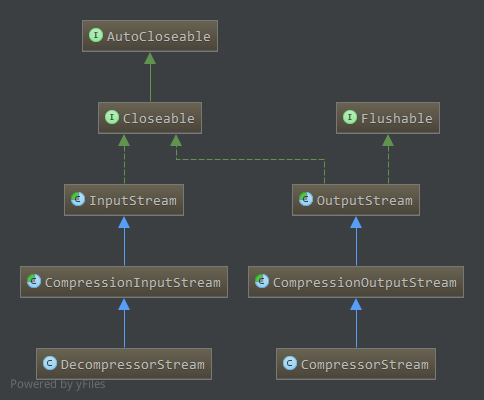
压缩流对应CompressionOutputStream,继承自OutputStream,为抽象类1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26public abstract class CompressionOutputStream extends OutputStream {
//底层输出流,最终压缩数据输出至此
protected final OutputStream out;
protected CompressionOutputStream(OutputStream out) {
this.out = out;
}
public void close() throws IOException {
finish();
out.close();
}
public void flush() throws IOException {
out.flush();
}
//数据b压缩后写入底层流中
public abstract void write(byte[] b, int off, int len) throws IOException;
//完成向底层流写入压缩数据,底层流未关闭
public abstract void finish() throws IOException;
//重置压缩为初始状态,底层流不重置
public abstract void resetState() throws IOException;
}
而CompressorStream使用压缩器实现了一个通用的压缩流,给定不同压缩器便得到相应压缩器的压缩流。
成员属性
1
2
3protected Compressor compressor;//压缩器
protected byte[] buffer;//压缩结果暂存缓冲
protected boolean closed = false;构造
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18protected CompressorStream(OutputStream out) {
super(out);
}
public CompressorStream(OutputStream out, Compressor compressor) {
this(out, compressor, 512);
}
public CompressorStream(OutputStream out, Compressor compressor, int bufferSize) {
super(out);//底层流
if (out == null || compressor == null) {
throw new NullPointerException();
} else if (bufferSize <= 0) {
throw new IllegalArgumentException("Illegal bufferSize");
}
this.compressor = compressor;
buffer = new byte[bufferSize];
}流的写操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public void write(byte[] b, int off, int len) throws IOException {
// 合理性检查
...
//写到压缩器的缓冲
compressor.setInput(b, off, len);
while (!compressor.needsInput()) {//需要压缩时压缩并输出到底层流
compress();
}
}
protected void compress() throws IOException {
int len = compressor.compress(buffer, 0, buffer.length);//压缩
if (len > 0) {
out.write(buffer, 0, len);//写到底层流
}
}
private byte[] oneByte = new byte[1];
public void write(int b) throws IOException {
oneByte[0] = (byte)(b & 0xff);
write(oneByte, 0, oneByte.length);
}状态相关
等待完成finish方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public void finish() throws IOException {
if (!compressor.finished()) {
compressor.finish();//终止输入
while (!compressor.finished()) {//压缩并输出剩余数据
compress();
}
}
}
public void resetState() throws IOException {
compressor.reset();
}
public void close() throws IOException {//关闭压缩流,包括底层流
if (!closed) {
finish();
out.close();
closed = true;
}
}
解压流类似,不再分析。